
The Real Cost of Background Coding Agents: How Token Burn Adds Up in 2026
Taher Pardawala June 24, 2026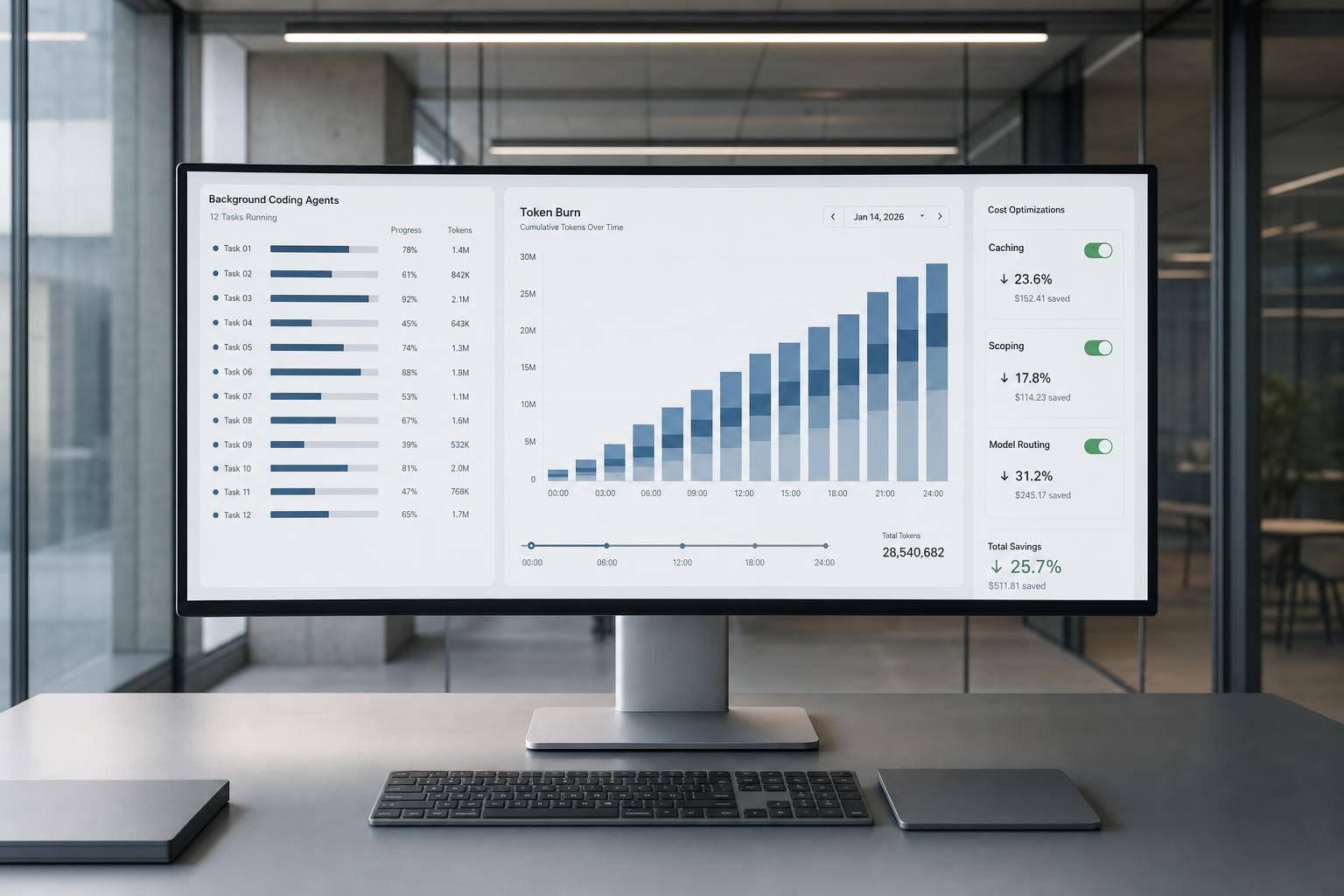
The short version: background coding agents often cost more from repeated input than from the code they write. In the example here, one 50-turn session can run about $3.60 uncached or about $1.04 with cache reads. And when you run several agents at once, spend can jump to 3x to 4x the baseline because each one reloads prompts, tools, and repo context.
If I had to boil the article down to a few points, it would be this:
- Input tokens drive most of the bill: about 85% of session cost
- Repeated context is the main problem: old chat history, tool output, and repo reads keep getting sent again
- Parallel agents multiply waste: the same files and setup can be billed many times
- Caching helps a lot: cached reads can cut repeated-prefix cost by up to 90%
- Scope matters: smaller file slices, fewer turns, and less agent-to-agent chatter cut spend fast
- Model routing matters too: cheaper models fit small edit tasks better than top-tier models
A few numbers make the point fast:
| Item | What it shows |
|---|---|
| 25:1 | Input tokens vs. output tokens in a typical agentic coding session |
| 62% | Share of the bill tied to resent context |
| 10,000 to 60,000 | Extra tokens per turn from tool definitions in some MCP setups |
| $12 to $30 | Cost range for a naive 5-agent run |
| $5 to $12 | Cost range for a tighter 5-agent setup |
So if you’re budgeting for coding agents in 2026, I’d focus less on the sticker price per million tokens and more on how often the same context gets re-read. That’s where token burn starts to stack up.
Where token costs actually build up in agent workflows
How conversation growth drives repeated context reads
Each turn resends the full conversation history. So the same earlier context gets billed again and again. That’s where token burn starts to snowball.
With every new turn, the transcript gets longer. And the cost curve doesn’t grow in a straight line, because each turn adds more text that later turns must send back to the model [8]. In Vantage‘s 2026 example, input tokens per turn can grow from about 5,000 during early exploration to around 20,000 during implementation, then to 35,000 during testing and iteration [7]. That means a 20-step agent loop can use more than 10x the tokens that a simple per-step estimate would suggest [8].
"The expensive part isn’t any individual turn. It’s the accumulation… Turn 1 might send 5,000 input tokens. By turn 30, the model is carrying 25,000-35,000 input tokens." – Vantage [7]
Tool calls, retrieval, and summarization passes
Tool calls add extra baggage to the context window. Search results, shell commands, and code snippets get appended to the history, then sent again on later turns. Research shows that 39.9% to 59.7% of tokens in a typical agent history come from tool results that add no performance gain [8]. In debugging sessions, old grep output, stack traces, and test logs can sit in context long after they stop being useful.
There is another cost that often slips by: tool-call payloads and tool definitions themselves. In multi-server Model Context Protocol (MCP) setups, those can add 10,000 to 60,000 tokens per turn [4].
Summarization or compaction can shrink the active window, which sounds like an easy fix. But there is a catch. It can break prompt caching and cause the next turn to be billed at full price [10].
Those hidden re-sends become much easier to spot in a step-by-step session model.
Long outputs and parallel branches
Input tokens account for about 85% of session costs [6][3], so trimming response length usually doesn’t change total spend much. The bigger issue is repeated input.
The pattern gets more expensive when agents run in parallel. Each agent keeps its own separate context window. So if several agents read the same shared utility files, those files are loaded and re-sent in each session, one by one. Same file, same tokens, billed multiple times.
| Session Phase | Turns | Avg. Input Tokens/Turn | Avg. Output Tokens/Turn |
|---|---|---|---|
| Exploration | 1–10 | ~5,000 | ~600 |
| Implementation | 11–30 | ~20,000 | ~1,000 |
| Testing & Iteration | 31–50 | ~35,000 | ~800 |
| Total (50 turns) | 50 | ~1,150,000 | ~42,000 |
That duplication is what the worked example below makes visible. The next section turns this pattern into a transparent session example.
sbb-itb-51b9a02
An illustrative cost model for one background agent session
Illustrative scenario: one agent reviewing, editing, and revising code across multiple steps
To make the cost pattern concrete, the numbers below are illustrative only. They use official pricing and documented agent usage patterns, with the assumptions spelled out so you can swap in your own repo size, turn count, or model.
Assumed setup: One background agent running on Claude Sonnet 4.6 ($3.00/MTok input, $15.00/MTok output, $0.30/MTok cache read [2]). Anthropic says cached reads cost about 10% of normal input [2][6]. This task is modeled at about 50 turns. It starts with a 50,000-token system prompt and repository map, then moves through discovery, planning, edit-test loops, verification, and a final PR summary. Prompt caching is turned on for repeated context. No single step is costly on its own. The spend builds because the agent keeps reprocessing accumulated history on each turn, plus tool calls and the occasional summarization pass.
In this 50-turn example, the uncached total comes to about $3.60. With cached reads, that drops to about $1.04. Add a 20% buffer, and the uncached estimate moves to $4.32 [11][6].
Token cost table for the illustrative example
The table below breaks the session into five phases. Every figure is illustrative. The Cost (No Cache) column assumes all input tokens are billed at the full rate. The Cost (Cached Repeats) column assumes repeated context is billed at the cache read rate after the first write.
| Session Phase | Illustrative Input Tokens | Illustrative Output Tokens | Cost (No Cache) | Cost (Cached Repeats) |
|---|---|---|---|---|
| 1. Setup – instructions + repository map | 50,000 | 500 | $0.15 | $0.15 |
| 2. Planning – file reads + strategy | 150,000 | 2,000 | $0.48 | $0.08 |
| 3. Execution – 10× edit-test loops | 500,000 | 25,000 | $1.88 | $0.53 |
| 4. Review – verification + fixes | 250,000 | 10,000 | $0.90 | $0.23 |
| 5. Summary – final PR description | 50,000 | 2,500 | $0.19 | $0.05 |
| Total (50 turns) | 1,000,000 | 40,000 | $3.60 | $1.04 |
Rounded to the nearest cent.
Source: Anthropic official pricing and documented agentic usage patterns [2][6][11]
The execution phase alone, just 10 edit-test loops, makes up about half of the input tokens and a bit more than half of the uncached cost. That’s the compounding effect in plain terms: the agent keeps paying to reread its own history, not just to produce new output. And when multiple agents run at the same time, that duplicated rereading stacks up fast.
AI Testing Costs, How to Prevent Runaway Token Bills
Why parallel agents push spend up faster than expected
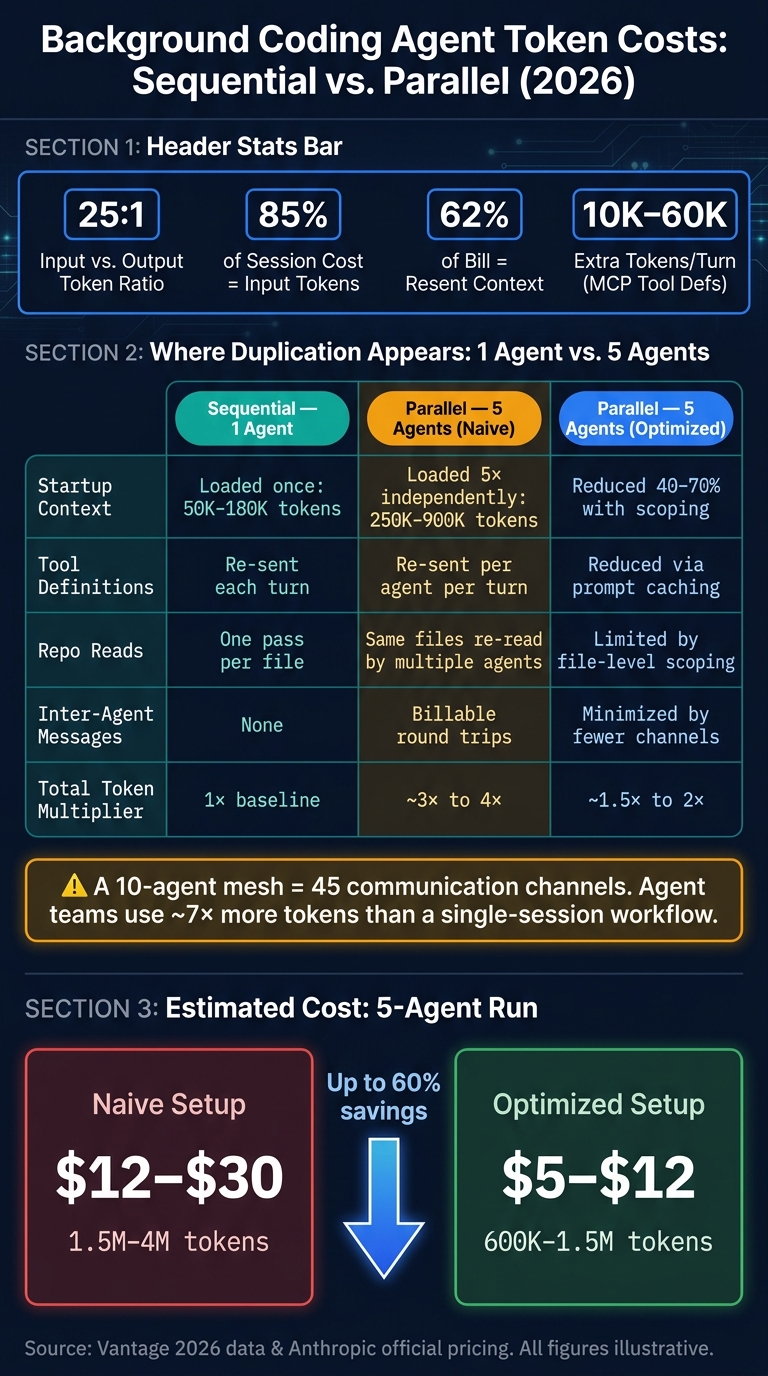
Background Coding Agent Token Costs: Sequential vs. Parallel Workflows (2026)
The single-agent example makes costs look smaller than they often are. In practice, every added agent repeats the same setup work: startup context, tool definitions, and repo reads. The extra spend starts before any real coding begins.
Sequential versus parallel workflows: a direct comparison
Each agent has to load the same system prompt, tools, and repo context again. In a medium-sized codebase, startup context alone can hit 50,000 to 180,000 tokens per agent, so five agents can burn 250,000 to 900,000 tokens before a single line of code is touched [13].
Parallel workflows only make sense when tasks are fully separate, like work on different modules with no shared files or interfaces. Once agents start touching the same files or connected interfaces, things get messy. Different snapshots can lead to merge conflicts, and fixing those conflicts often means yet another token-heavy pass.
A naive five-agent run can use 1.5 million to 4 million tokens ($12 to $30). With tighter scoping and model tiering, that drops to 600,000 to 1.5 million tokens ($5 to $12) [13].
Comparison table: where duplication appears in multi-agent runs
The table below shows where the duplication shows up in a multi-agent workflow.
| Duplication Layer | Sequential (1 Agent) | Parallel (5 Agents, Naive) | Parallel (5 Agents, Optimized) |
|---|---|---|---|
| Startup context | Loaded once (50K–180K tokens) [13] | Loaded 5× independently (250K–900K tokens) [13] | Reduced 40%–70% with .claudeignore scoping [13] |
| Tool definitions | Re-sent as part of each turn | Re-sent per agent on each turn | Reduced with prompt caching for stable context [9] |
| Repo reads | One pass per file needed | Same files can be re-read by multiple agents [14] | Limited by tighter file-level task scoping |
| Inter-agent messages | None | Billable round trips through the model [1] | Minimized by reducing coordination channels |
| Summarization cycles | One per long session | One per agent per long session | Reduced by resetting sessions between tasks [13] |
| Total token multiplier | 1× baseline | Roughly 3× to 4× [13] | Roughly 1.5× to 2× [13] |
Coordination overhead stacks up fast. A five-agent mesh has ten communication channels. A ten-agent mesh has forty-five [4]. Every channel creates a billable round trip. That’s why agent teams, where agents actively message each other, are the most expensive orchestration mode. They typically use about 7× more tokens than a comparable single-session workflow [2][12].
The main issue is simple: are the tasks actually independent? If not, sequential execution is usually cheaper and easier to manage. That shifts the focus from model price alone to the duplicated work each task creates.
How to control token spend without losing engineering value
When repeated processing is the problem, the fix is simple in principle: make each agent reprocess less.
Cut unnecessary context and background activity
Start by shrinking what each agent carries. Load only the method or file slice needed for the task at hand, not the entire repo. And instead of sending full file contents to subagents, pass file paths. That keeps the orchestrator’s context more stable and easier to cache [5].
Background loops can burn through budget fast. In naive agent loops, the full history gets resent on every call, so cost climbs faster than linearly as tool output and reasoning pile up [8]. One practical move is to compress context every 10 to 15 tool calls. That alone can cut token use by 22.7% [8]. For long sessions, reset them and keep only task status and file paths in external storage [8].
Once context is leaner, the next step is routing each task to the cheapest model that can still get the job done.
Match task type, model choice, and parallelism to business value
Not every task needs the top-priced model. Formatting, linting, and tight edits can run on Claude Haiku 4.5 at $1.00 per million input tokens, while broader reasoning or orchestration can shift to Claude Sonnet 4.6 or Opus 4.8 [2]. A tiered setup with one Opus orchestrator, three Sonnet workers, and one Haiku costs about 40% less than running five Opus agents [2].
For inputs that stay the same, like system prompts and tool definitions, prompt caching is one of the best cost controls. Cached reads cost 10% of the base input price, which can cut repeated-prefix spend by up to 90% [9]. If a job isn’t time-sensitive, the Batches API gives a flat 50% discount on both input and output rates [15]. And parallel agents should run only when the added output is worth the multiplied cost [16].
This is why these controls matter: they cut duplicate processing across turns, tools, and branches.
Conclusion: the real cost is repeated processing, not just the model rate
Token spend in agent workflows doesn’t rise from model rates alone. It rises because the same context gets read, re-read, and billed again across every turn, every tool call, and every parallel branch. Repo reads, tool-schema overhead, summarization cycles, and inter-agent coordination can all stack up before the task is even done.
The worked examples earlier in this article help build intuition and make budget planning easier before a workflow goes live. But the main lever is disciplined workflow design: tighter scopes, smarter model routing, aggressive caching, and hard caps on iterations and subagent depth. Teams that budget for agent behavior, not just per-token model rates, are the ones that keep AI-assisted delivery sustainable as these workflows scale.
FAQs
Why do input tokens cost more overall than outputs?
Per token, input isn’t more expensive. In most cases, output tokens cost about 5x more.
But here’s the catch: input tokens usually drive most of the total bill.
Why? Because agents tend to resend the full built-up context again and again. That often includes:
- system prompts
- tool definitions
- conversation history
So even if output has the higher per-token price, a roughly 25:1 input-to-output ratio can make input the main cost driver.
When are parallel coding agents worth the extra spend?
Parallel coding agents are worth the extra spend when speed matters more than cost, especially on long, complex tasks where better context handling can save a lot of time.
They work best when the job can be split into independent pieces. Think frontend and backend refactoring, where each part can move forward without constant back-and-forth. They can also help on very long projects, because they avoid the growing input token costs that come with one 100+ turn conversation.
That said, they usually don’t pay off for short tasks or tightly coupled code. In those cases, coordination overhead and repeated context can eat into the time you hoped to save.
What’s the fastest way to cut token burn?
The fastest way to cut token burn is to use prompt caching for system prompts, tool definitions, and stable codebase context.
Why does this matter? Agents send that same stuff again on every step. If you cache it, those tokens can cost about 10% of the normal input rate. In plain English, that often cuts that part of the bill by 90%.
A simple way to set it up:
- Keep a stable prompt prefix
- Put changing user messages at the end
- Leave dynamic data out of cached blocks
That structure helps you avoid paying full price again and again for the same repeated context.
Related Blog Posts
- AI Coding Tools in 2026: What We Actually Use Across 20+ Client Projects (And What We Don’t)
- The Hidden Complexity in Multi-Agent Orchestration That Every Demo Skips Over
- Self-Hosted SLMs for Regulated Industries: Architecture, Cost, and Compliance Trade-offs We’ve Navigated
- Antigravity vs Cursor vs Claude Code: How the Three Agentic Coding Tools Compare for Production Work in 2026






Leave a Reply