
Self-Hosted SLMs for Regulated Industries: Architecture, Cost, and Compliance Trade-offs We’ve Navigated
Huzefa Motiwala May 2, 2026
Self-hosting language models (SLMs) is becoming essential for industries like healthcare, pharma, and finance due to strict compliance requirements. Here’s why and how organizations are making this shift:
- Why Self-Host? Cloud APIs often fail to meet privacy laws like HIPAA and GDPR, risking fines and data breaches. Self-hosting ensures data sovereignty, reduces compliance risks, and eliminates reliance on third-party processors.
- Deployment Options: Choose between bare metal (maximum control, high cost), Kubernetes (scalable, complex), or managed inference (low effort, limited control).
- Costs: Initial hardware investments (e.g., NVIDIA H100 GPUs at $30,000–$40,000 each) and engineering labor can be steep, but self-hosting becomes cost-effective with high token volumes or sensitive data workloads.
- Compliance Features: Implement strict data residency, robust access controls (RBAC/ABAC), and immutable audit logs to meet regulations like GDPR, HIPAA, and the upcoming EU AI Act.
This article explores the architecture, costs, and trade-offs of self-hosting SLMs, helping you decide if it’s the right approach for your organization’s needs.
Self-Hosting LLMs: Architect’s Guide to When & How
sbb-itb-51b9a02
Deployment Architecture Options: Bare Metal, Kubernetes, and Managed Inference
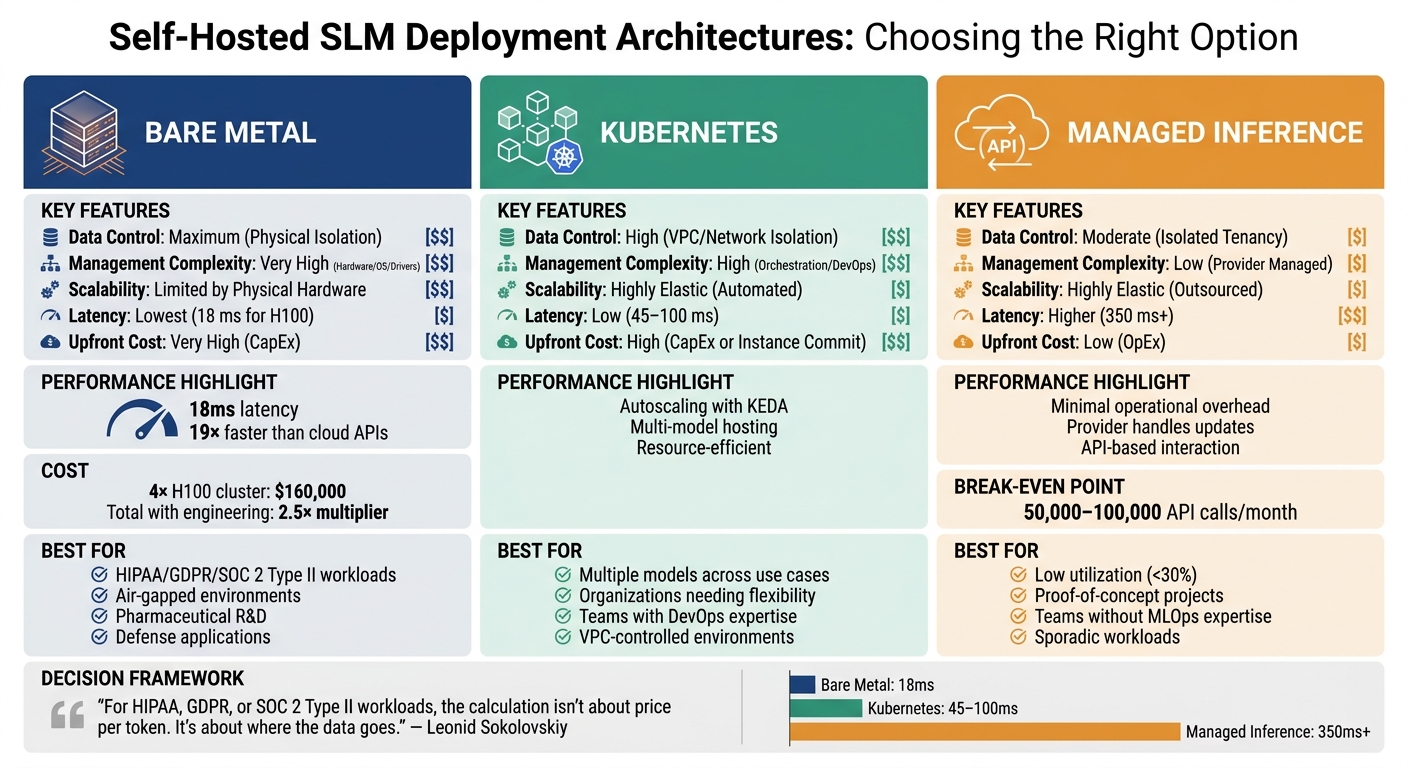
Self-Hosted SLM Deployment Architecture Comparison: Bare Metal vs Kubernetes vs Managed Inference
When it comes to deployment, you’ve got three main options: bare metal, Kubernetes, and managed inference. Each choice strikes a different balance between control, complexity, and cost, depending on your specific regulatory requirements and engineering capabilities. Let’s break down the pros and cons of each.
Bare Metal: Maximum Control and Performance
Bare metal involves running inference directly on physical servers that you own and operate. This approach eliminates any virtualization overhead and ensures complete physical isolation. For industries like pharmaceutical R&D or defense, where strict air-gapping is a must, bare metal is often the only compliant option [9][8].
The standout feature here is performance. Bare metal can achieve latencies as low as 18 milliseconds, which is 19 times faster than typical cloud API endpoints. This makes it ideal for applications like real-time diagnostics or high-frequency trading, where every millisecond counts [5].
However, the trade-off is cost and complexity. A production-grade 4x H100 cluster can set you back about $160,000 upfront. Add to that a 2.5x multiplier for engineering and maintenance, and it’s clear that this route demands significant investment [5][2]. Scaling is another challenge – adding capacity requires ordering, configuring, and deploying new servers, which can take weeks.
"For HIPAA, GDPR, or SOC 2 Type II workloads, the calculation isn’t about price per token. It’s about where the data goes." – Leonid Sokolovskiy, Level Up Coding [12]
Bare metal is the go-to option when low latency and strict data control are non-negotiable. It’s particularly suited for workloads requiring stringent compliance with regulations like HIPAA or GDPR [9][5].
Kubernetes: Scalable and Portable Deployments
Kubernetes offers a middle ground, delivering scalability and flexibility. It automates GPU management using operators, supports resource-efficient multi-model hosting, and allows you to scale models independently based on traffic [13][5].
This setup is perfect for organizations juggling multiple models across various use cases. Kubernetes shines with its autoscaling capabilities, like KEDA, which lets you adjust resources during peak times and scale down when demand drops. Unlike bare metal, this elasticity doesn’t require purchasing additional hardware and avoids the vendor lock-in of managed services.
That said, Kubernetes comes with its own set of challenges. Managing GPU scheduling, device plugins, and cluster upgrades requires a skilled platform engineering team. For teams new to container orchestration, the learning curve can be steep, and hiring DevOps experts with Kubernetes experience may be necessary [9][7].
For organizations needing to manage a fleet of models while maintaining control over their VPC, Kubernetes is a solid choice. It’s especially relevant in regulated environments where flexibility and scalability are prioritized over the absolute control of bare metal [13][5].
Managed Inference: Convenience vs. Control
Managed inference solutions, like Azure OpenAI or AWS Bedrock, offer the easiest path to deployment with minimal operational overhead. The cloud provider takes care of hardware provisioning, updates, and model serving, allowing you to interact via API within your own isolated network.
This option is particularly appealing for workloads with low utilization (under 30%) or for teams without significant MLOps expertise. The low upfront costs and high elasticity make it ideal for proof-of-concept projects or sporadic workloads [5].
However, you’ll face trade-offs in control and cost. Vendor lock-in is a concern, as you rely on the provider to maintain compliance and data residency. Costs also scale with usage, and at high volumes, managed inference can become far more expensive than self-hosting. The financial break-even point typically falls between 50,000 and 100,000 API calls per month [2][14].
"Self-hosting rarely saves money until you’re spending serious monthly volume on API calls – the break-even is GPU amortization plus one full-time SRE, not just the hardware bill." – Asad Ali, ZTABS [14]
Managed inference is best for quick prototypes or workloads with low usage. However, for production workloads involving sensitive data, transitioning to self-hosted infrastructure often becomes necessary as usage grows. For instance, in January 2026, a 400-bed health system in the Midwest moved from a cloud LLM solution to a self-hosted instance of Llama 3.1 to ensure clinical data stayed off the public internet [2].
Comparing the Options
Here’s a quick summary of how these three deployment architectures stack up:
| Feature | Bare Metal | Kubernetes | Managed Inference |
|---|---|---|---|
| Data Control | Maximum (Physical Isolation) | High (VPC/Network Isolation) | Moderate (Isolated Tenancy) |
| Management Complexity | Very High (Hardware/OS/Drivers) | High (Orchestration/DevOps) | Low (Provider Managed) |
| Scalability | Limited by Physical Hardware | Highly Elastic (Automated) | Highly Elastic (Outsourced) |
| Latency | Lowest (18 ms for H100) | Low (45–100 ms) | Higher (350 ms+) |
| Upfront Cost | Very High (CapEx) | High (CapEx or Instance Commit) | Low (OpEx) |
Each option comes with its own set of strengths and weaknesses, so your choice will depend heavily on your specific workload, compliance requirements, and budget.
Model Quantization: Cost vs. Quality for Compliance-Sensitive Tasks
Once you’ve chosen your deployment, the next critical step is quantization – compressing your model to fit within available GPU memory. This decision directly impacts hardware expenses, inference speed, and accuracy. In industries with strict regulations, even a small accuracy drop (2–5%) can mean the difference between a correct clinical diagnosis and a dangerous mistake. As such, quantization isn’t just a technical choice; it’s a cornerstone of compliance and safety.
4-bit, 8-bit, and FP16: Balancing Speed, Memory, and Accuracy
FP16, the 16-bit floating point standard, provides the highest accuracy but comes with steep GPU memory requirements. For example, running a 70B-parameter model in FP16 demands about 140GB of VRAM, meaning you’d need at least two A100 80GB GPUs – each costing roughly $15,000 [14]. This level of precision is essential for production clinical workloads where patient safety is a top priority.
On the other hand, 8-bit quantization (INT8) cuts memory usage by half while maintaining nearly the same accuracy – usually less than a 1% drop [14]. It offers similar inference speeds to FP16 and is widely used in regulated workflows that don’t involve direct patient care [17]. For a 70B model, 8-bit quantization reduces VRAM needs to around 70GB, which can often run on a single H100 80GB GPU.
For more aggressive memory savings, 4-bit quantization (using methods like GPTQ or AWQ) slashes memory usage by about 75%, enabling a 70B model to run on just 36–40GB of VRAM [2] [14]. However, this comes at a cost: accuracy can drop by 2–5% on benchmarks [2]. In scenarios where patient care is directly affected, this trade-off is often unacceptable.
"For production clinical workloads, we recommend FP16 or BF16 – the accuracy tradeoff isn’t worth the hardware savings when patient care is involved." – Nirmitee.io [2]
While 4-bit models can deliver faster inference by alleviating memory bottlenecks [14], precision takes precedence over speed in critical applications. These quantization strategies are especially important in addressing the stringent accuracy demands of pharmaceutical research.
Pharma Workflows: Precision Matters in Drug Discovery
In pharmaceutical R&D, there’s no room for error. Tasks like drug discovery, clinical trial analysis, and compound screening require absolute accuracy. Even minor losses in precision can have massive consequences in these high-stakes environments. With predictions that 30% of new drugs in 2025 will involve AI and that AI could reduce R&D timelines by as much as 70–80% [16], the need for reliable predictions has never been greater.
For such tasks, FP16 or BF16 is the only viable option. While the upfront costs of dual A100 or H100 GPUs may seem high, the potential losses from a failed drug candidate or regulatory hurdle far exceed these expenses. Models like Med42-Llama3.1-70B, which achieve around 95% accuracy on the USMLE, rely on full precision to maintain their advanced clinical reasoning capabilities [2].
That said, not all pharmaceutical tasks require maximum precision. Administrative tasks, such as creating patient education materials or formatting regulatory documents, can make effective use of 4-bit or 8-bit quantization to optimize hardware usage [2]. The key is tailoring quantization to the specific requirements of each task.
Healthcare Tasks: Precision for PHI-Sensitive Work
Healthcare organizations face similar challenges when it comes to balancing accuracy and efficiency. For tasks like clinical reasoning, diagnostic support, and patient triage – where decisions directly affect patient outcomes – FP16 remains the gold standard. Benchmarks like the USMLE are often used to assess a model’s suitability for clinical use. Models such as Med42-Llama3.1-70B, with their 95% accuracy, have proven competitive with proprietary solutions [2] [16]. To further ensure accuracy, organizations are encouraged to develop internal evaluation tools tailored to their unique workflows and terminology [2].
For less critical operations, such as appointment scheduling summaries, administrative document generation, or basic classification tasks, 8-bit quantization can significantly improve throughput without noticeable quality loss [17].
A dual A100 80GB GPU setup for healthcare tasks costs approximately $3,200 per month, including operational expenses [2]. Aligning the precision of your quantization approach with your deployment strategy ensures that your self-hosted solution meets both performance and compliance requirements.
Data Residency Implementation for GDPR and HIPAA
Keeping sensitive data under strict control is a must for industries bound by regulations like GDPR and HIPAA. This means setting up systems that ensure Protected Health Information (PHI) and personal data stay within specific legal boundaries. The focus isn’t just about compliance – it’s about removing the need for third-party data processing altogether.
After addressing deployment and quantization strategies, securing data residency becomes the next key step in maintaining compliance.
On-Premises Network Isolation
One effective strategy is deploying within a Virtual Private Cloud (VPC), where every component that handles sensitive data – like GPU clusters, model servers, databases, and audit loggers – operates within a single, isolated environment. This setup ensures patient data stays inside existing HIPAA-compliant infrastructure without requiring additional Business Associate Agreements [2]. By configuring inference servers to use private endpoints (e.g., 127.0.0.1 or specific VPC addresses), PHI is kept entirely within the network’s perimeter. Moreover, a properly configured VPC boundary simplifies GDPR compliance by preventing cross-border data transfers. As noted by ZeroClaws.io:
"The difference isn’t that self-hosting eliminates GDPR obligations… The difference is that self-hosting eliminates the third-party processing layer that creates most of the compliance complexity." – ZeroClaws.io [1]
To further secure the network, firewall tools like ufw can block all outbound traffic by default on AI servers, reducing the risk of data leaks even if the system is compromised [11]. For data moving within the VPC, enforce TLS 1.3+ encryption protocols. When storing data – such as model weights or vector embeddings – use AES-256 encryption on OPAL 2.0 SSDs [4].
For environments needing even tighter control, consider air-gapped architectures.
Air-Gapped Architectures
In high-risk scenarios, such as pharmaceutical R&D labs handling proprietary data or clinical trials with sensitive protocols, air-gapped architectures provide the highest level of isolation. These setups are completely disconnected from the public internet – no telemetry, update checks, DNS lookups, or licensing server communications [9].
To implement this, configure the system without a default gateway (e.g., using netplan on Linux to exclude the gateway4 entry), effectively preventing any internet routing [11]. Updates, model weights, and software patches must be downloaded, verified via checksums, and transferred to the secure environment through encrypted physical media [9].
One challenge with air-gapped systems is maintaining security monitoring. Logs and metrics still need to be exported to a Security Information and Event Management (SIEM) system for threat detection. Here, data diodes – tools that allow one-way outbound data flow – can be used to send logs out of the air-gapped zone while blocking any inbound communication [3].
These stringent methods of isolation are particularly suitable for tailored configurations in healthcare and pharmaceutical environments.
Pharma and Healthcare Implementation Examples
Here are some examples of how data residency strategies can be integrated into deployment architectures to meet compliance needs while maintaining efficiency:
- Pharmaceutical R&D: A hybrid approach is often used for PHI-aware routing. A gateway layer analyzes incoming prompts for sensitive information. Queries containing PHI are directed to local servers, while non-sensitive tasks can be processed via cloud APIs to optimize costs [2].
- Healthcare Providers: Small-scale setups, like a dental office running a local AI server for tasks such as summarizing patient records or managing appointment schedules, are a practical example. These setups might include mid-range GPUs and ECC RAM to ensure data stays local. Models like Whisper Large v3 (requiring just 3GB VRAM) can handle medical transcription, while Llama 3.1 8B can assist with clinical natural language processing tasks [11].
- Large-Scale Pharma Organizations: Enterprise-grade clusters, such as those with 8× H100 80GB GPUs (costing between $250,000 and $350,000), are designed for intensive drug discovery workflows. These setups often integrate Differential Privacy Stochastic Gradient Descent (DP-SGD) during model fine-tuning, adding noise to gradient updates to prevent the reconstruction of individual training records from model outputs [18].
These examples highlight how tailored data residency solutions can meet the specific needs of various healthcare and pharmaceutical environments while ensuring compliance with GDPR and HIPAA requirements.
Access Control and Audit Logging for LLM Inference
Once data residency is secured, controlling access to your models and maintaining detailed records of every interaction become critical for compliance. Regulations like HIPAA require accountability for access to Protected Health Information (PHI) [16], GDPR mandates transparency around automated decisions [16], and the EU AI Act emphasizes traceability for high-risk systems, with obligations starting August 2, 2026 [21]. Without stringent access controls and tamper-proof logs, even isolated SLMs could fail compliance audits.
RBAC and ABAC Implementation
Role-Based Access Control (RBAC) assigns access based on predefined roles, such as Researcher, Clinician, or Admin. It’s a fundamental HIPAA requirement [16] and works well for managing broad policies. For example, it can restrict which teams access specific model endpoints or vector stores in Retrieval-Augmented Generation workflows [16].
Attribute-Based Access Control (ABAC) takes this a step further by factoring in user, resource, and environmental attributes. Instead of simply asking, "Is this user a Researcher?", ABAC evaluates conditions like whether the user is accessing a model trained on Controlled Unclassified Information (CUI) from an approved network during business hours [20][16]. This added precision is essential for environments like pharma R&D labs, where data often has multiple sensitivity levels. ABAC can also dynamically filter RAG results, ensuring unauthorized users don’t see restricted context [16].
For high-stakes tasks like model retraining or exporting logs, RBAC can be paired with temporary credentials and session recording to meet chain-of-custody requirements [20].
With robust access controls in place, an immutable audit trail is the next critical step for verifying every interaction.
Immutable Audit Trails
Every inference request must be logged in a way that prevents alteration or deletion – even by database administrators. This can be enforced with SQL-level immutability using commands like:
REVOKE DELETE, UPDATE ON audit_events FROM ALL; To ensure logs are tamper-evident, implement hash chaining, where each log entry includes the SHA-256 digest of the previous entry. This forms a Merkle tree, with the root hash anchored in an external tamper-proof system, such as a blockchain or an RFC 3161 timestamping service [21]. Auditors can then verify the integrity of the entire log chain efficiently, in O(log n) time.
A tiered storage setup is ideal for managing logs:
- Hot tier: Use tools like PostgreSQL or TimescaleDB for real-time queries over 30–90 days.
- Warm tier: Systems like Apache Kafka can handle SIEM integration for up to a year.
- Cold tier: Long-term storage (6–10 years) can be managed with services like S3 or GCS, using WORM policies [21][20].
"The audit trail is not a feature you add later. It is part of the architecture from day one." – Daniella Mitchell, The BrightByte [21]
Additionally, a proposed HIPAA update expected in 2025 – and likely finalized by May 2026 – will require AES-256 encryption for data at rest and TLS 1.2+ for data in transit, removing the previously "addressable" distinction [21].
| Audit Log Field | Purpose for Compliance |
|---|---|
timestamp |
Establishes a timeline for forensic investigations |
user_id / key_id |
Ensures accountability and attribution for access |
prompt_hash |
Identifies content without storing sensitive data |
status |
Indicates if a request succeeded, failed, or was blocked |
reason |
Logs guardrails triggered (e.g., PII filter, rate limit) |
client_ip |
Tracks network origin for anomaly detection |
After securing logs, real-time monitoring strengthens defenses against unauthorized activity.
Real-Time Monitoring for Inference Pipelines
Real-time monitoring is vital for spotting unauthorized access or anomalies. Instead of exposing inference engines (like Ollama or vLLM) directly, use a proxy (e.g., LiteLLM) to manage authentication, issue virtual keys for users or applications, and handle routing [22].
"The moment your self-hosted LLM has more than three users, ‘everyone hits the same Ollama port’ stops being a tenable design." – LocalAimaster Research Team [22]
Forward success and failure callbacks from the proxy to a SIEM platform (like Datadog) or an immutable S3 bucket for real-time alerts [21]. Automated playbooks can flag suspicious activity, such as repeated access failures, unusually large outputs (potentially signaling data exfiltration), or SQL injection attempts [21]. Rate and concurrency limits help prevent resource exhaustion or unexpected costs [22].
For GDPR compliance (Articles 13–15), log metadata that explains the decision-making process – like SHAP values or counterfactual explanations. This is especially critical for high-risk AI systems under the EU AI Act, which imposes penalties of up to €35 million or 7% of global annual turnover [16].
Finally, use network segmentation to isolate your inference pipelines. Internal-only Docker networks or dedicated VPCs with no external IPs are effective solutions. Outbound traffic should be limited strictly to model registries and SIEM collectors [22].
Total Cost of Ownership: Self-Hosted SLMs vs. Cloud LLM APIs
When evaluating self-hosting large language models (LLMs), financial considerations go far beyond compliance. The key drivers are token volume, GPU usage, and engineering costs. Since 70–90% of AI operational expenses come from inference rather than training [5], understanding these factors is critical – more so than many CTOs might anticipate. Below, we dive into the hardware investments, token thresholds, and maintenance efforts that shape the economics of self-hosting.
Hardware Costs and Engineering Overhead
The initial hardware expense is just one piece of the puzzle. For example, an NVIDIA H100 costs $30,000–$40,000 per unit [5][17], while the NVIDIA L40S ranges from $6,000–$9,000 [6]. However, the total cost of ownership (TCO) can be 2–3.5× the raw GPU price when you factor in engineering labor, MLOps tools, monitoring stacks like Prometheus and Grafana, and redundancy across multiple availability zones for reliability [25].
Setting up a self-hosted system isn’t quick or cheap. Deploying a production-grade model typically requires 2–4 full-time engineers working for 3–6 months, costing around $200,000–$300,000 in labor before you even serve a single token [28]. Once operational, running a 70B model on two reserved H100 instances can cost $13,275 per month, broken down as follows:
- Primary compute: $5,100
- Failover compute: $2,550
- MLOps engineer time (20% allocation): $3,200
- Monitoring tools: $420
Additionally, senior engineers may spend $6,600 per month on tasks like server maintenance, alongside costs for electricity, cooling, and infrastructure [23].
"Self-hosting AI inference is like running your own email server. You can do it… But for most organizations, the question is not whether you can – it is whether you should." – Abhishek Sharma, Head of Engineering, Fordel Studios [25]
Token Volume Breakeven Analysis
Self-hosting becomes cost-effective only when your monthly token volume consistently exceeds 100–500 million and GPU utilization stays between 60–80% [17]. Below this threshold, idle hardware costs more than API usage. For instance, a team using an RTX 4090 (≈$1,600) can break even with a $200/month API cost in 8–10 months [24]. However, real-world utilization often averages 40–55% due to traffic spikes, meaning you might need 2–4× more capacity than simple average-load calculations suggest [17][28].
Here’s an example using AWS g6.12xlarge instances (4× L4 GPUs) for a self-hosted Llama 3.3 70B model:
- At 20% utilization, you process 207 million tokens per month at $15.94 per 1 million tokens, making it more expensive than a $3.00/M token API.
- At 40% utilization, costs drop to $7.97 per 1 million tokens, making self-hosting cheaper.
- At 80% utilization, costs fall further to $3.99 per 1 million tokens, significantly undercutting cloud APIs [17].
"The self-hosting cost advantage only materializes at scale most companies never reach. Below 50M tokens per day, you are almost certainly better off with an API." – Abhishek Sharma, Head of Engineering, Fordel Studios [25]
Ongoing Maintenance and MLOps Costs
Self-hosting also comes with recurring expenses that API users avoid. For instance, when a new model version (e.g., Llama 3.3 to Llama 4) is released, you’ll need 2–4 weeks of engineering time to test, validate, and deploy the update [25]. Routine tasks like security patches, CUDA driver updates, and regression testing add another 5–10 hours per month [26].
Beyond compute, there are other operational costs:
- Data egress fees: Around $0.09 per GB for data transferred out of AWS [23][17].
- High-speed object storage: $400–$600 per month for model weights, load balancers, and GPU telemetry monitoring [25][28].
For industries with strict regulations, the "risk-adjusted cost" of a potential data breach through third-party APIs often makes self-hosting the only option – though this is a decision driven by risk, not purely by cost [27][5].
| Utilization | Tokens/Month | Monthly Self-Hosting Cost | Cost per 1M Tokens | API Equivalent (Claude Sonnet) |
|---|---|---|---|---|
| 20% | 207M | $3,300 | $15.94 | $3,100 (API is cheaper) |
| 40% | 414M | $3,300 | $7.97 | $6,200 (Self-host wins) |
| 80% | 828M | $3,300 | $3.99 | $12,400 (Self-host wins) |
"An idle GPU is more expensive than the API. A 70%-utilized GPU is dramatically cheaper. The whole game is utilization." – Akshay Ghalme, DevOps Engineer, BytePhase Technologies [17]
This cost breakdown ties directly to deployment and resource optimization strategies. While self-hosting may address compliance needs, its financial success depends heavily on keeping GPUs busy and making the most of your infrastructure.
Architecture Patterns for Pharma and Healthcare
Pharma and healthcare systems face the dual challenge of maintaining high performance while adhering to strict compliance standards. The following architecture patterns highlight how real-world deployments tackle issues like data residency, audit trails, and latency.
Pharma: Drug Discovery Workflow Architecture
Drug discovery workflows demand secure, isolated environments with dedicated hardware to safeguard proprietary research. A common setup employs NVIDIA A100 or H100 GPUs, using Multi-Instance GPU (MIG) slicing to allocate dedicated GPU partitions for each research team [16]. These workflows operate within a Virtual Private Cloud (VPC) with no internet egress, ensuring maximum security [2][3].
To enable external monitoring without compromising security, data diodes are used. These devices allow logs and metrics to exit the secure zone for tools like Prometheus and Grafana but block any incoming commands [3]. Retrieval-Augmented Generation (RAG) systems are integrated with Role-Based Access Control (RBAC), ensuring that researchers only access documents they are authorized to view [16]. Additionally, all interactions are recorded in audit logs secured with cryptographic hashing [19][10].
"Data collected in a specific region is subject to the laws of that region." – TechRadar [3]
Generative AI has the potential to revolutionize the pharmaceutical industry, with estimates suggesting it could unlock $60–110 billion annually. Currently, 95% of companies in the sector are investing in AI [3][16]. By leveraging AI, the drug discovery timeline could shrink from roughly six years to just one [16].
While pharma benefits from isolated research clusters, healthcare systems require similarly tailored solutions to ensure the security of Protected Health Information (PHI) and maintain efficient operations.
Healthcare: Patient Triage Systems
Healthcare architectures must secure PHI while delivering fast, reliable performance. A typical design places the GPU cluster, load balancer, and FHIR server within a dedicated VPC, ensuring no internet egress [2][11]. Kubernetes NetworkPolicies further isolate PHI-sensitive workloads into restricted zones [29].
Requests are classified based on their sensitivity. For tasks involving PHI, such as patient summarization or risk stratification, requests are routed to local Specialized Language Models (SLMs) like Med42-Llama3.1-70B, which boasts 95% accuracy on USMLE-style questions [2]. Less sensitive queries, such as general Q&A or template generation, are processed via cloud APIs to optimize costs [2]. Local inference on an A100 GPU achieves a first-token latency of under 200ms, significantly outperforming cloud-based APIs, which often exceed 2 seconds [2].
Hardware selection plays a critical role in meeting compliance requirements. ECC (Error Correction Code) RAM prevents data corruption, while OPAL 2.0 SSDs offer hardware-level encryption to meet HIPAA standards without sacrificing performance [11]. Audit logs, which are retained for at least six years as per HIPAA guidelines, ensure accountability, with every query tied to a specific user ID through corporate IAM integration [3].
For a 200-bed hospital, self-hosting LLMs can become cost-effective quickly. At 50,000 LLM calls per month, the break-even point is typically reached within the first quarter. Monthly expenses drop from $1,650–$6,300 for HIPAA-compliant cloud APIs to around $87 for electricity and maintenance once the hardware is in place [11].
"The question is no longer whether to deploy LLMs – it’s where." – Nirmitee [2]
Both pharma and healthcare architectures increasingly rely on self-hosted SLM strategies for regulated environments. These systems are treated as validated tools under regulatory frameworks, with documented intended use, controlled inputs and outputs, and human oversight [3][16]. With the EU AI Act’s requirements for high-risk AI systems set to take effect on August 2, 2026 [16], these architecture patterns will only grow in importance.
Conclusion: Making the Right Trade-offs for Your Regulated Environment
Self-hosting SLMs involves balancing compliance, operational control, and costs. The best architecture for your needs depends on factors like token volume, latency, and regulatory deadlines. For workloads with around 50,000 LLM calls per month or those requiring strict PHI management, self-hosting can be a cost-efficient option. It also delivers sub-200ms first-token latency – something cloud APIs often can’t match [2].
"Self-hosting isn’t a binary decision. It’s a spectrum. And the wrong choice – either hosting when you don’t need to, or refusing to host when you do – costs money and velocity." – Brightlume Team [15]
However, self-hosting comes with added responsibilities. Your organization must handle governance tasks like maintaining dedicated SRE capacity, creating immutable audit trails, and using version-pinned models to satisfy auditors. These steps are essential for meeting strict regulatory requirements [2][6]. On the plus side, self-hosting provides complete data sovereignty. This means no BAAs, no cross-border data transfers, and protection from vendor-driven model updates that could disrupt reproducibility [8]. With the EU AI Act’s high-risk obligations set to take effect on August 2, 2026, such control becomes a compliance advantage [8].
Operational control also opens the door to flexible deployment strategies. A hybrid architecture – using self-hosted SLMs for sensitive tasks and cloud APIs for less critical workloads – often strikes the right balance. This setup ensures compliance while avoiding the cost of over-provisioning GPUs for every use case [2].
To help regulated organizations navigate these decisions, AlterSquare offers services like AI-Agent Assessment and Principal Council oversight. We audit your architecture, analyze token economics, and design deployment strategies that meet legal requirements without slowing down your engineering efforts. Whether you’re stabilizing a system ahead of migration or building a robust inference pipeline, we can identify hidden costs and ensure your compliance needs are met.
FAQs
How do I decide between bare metal, Kubernetes, and managed inference?
Bare metal provides maximum control and ensures data stays on-premises, making it a go-to for industries like healthcare and pharmaceuticals that have to meet strict compliance standards. However, this approach demands a lot of maintenance and technical expertise to manage effectively.
Kubernetes, on the other hand, offers scalability and automation, striking a balance between control and simplified management. It’s particularly suited to containerized environments, where managing workloads efficiently is key.
Meanwhile, managed inference streamlines deployment processes, but it often runs into challenges with regulations like GDPR or HIPAA, making it less ideal for compliance-heavy sectors. For workflows that require strict adherence to regulations, bare metal or Kubernetes are typically the better options.
What quantization level is safe for PHI or high-stakes decisions?
For tasks involving Protected Health Information (PHI) or high-stakes decisions, it’s best to stick with minimal or no aggressive quantization. Why? Because higher levels of quantization can harm a model’s reasoning and accuracy – qualities that are absolutely essential for compliance-sensitive tasks. When working with sensitive healthcare data, focus on methods that maintain the model’s ability to reason effectively. This ensures both compliance and accurate decision-making.
What do auditors expect for access control and immutable LLM logs?
Auditors demand strict access control that leverages role-based permissions, ensuring that only authorized individuals can perform LLM inference. Equally important are comprehensive and unchangeable audit logs that capture every inference activity. These logs are essential for preserving data integrity and providing traceability, especially in highly regulated industries like healthcare, pharmaceuticals, and fintech, where compliance is non-negotiable.
Related Blog Posts
- Building an AI Feature with Open-Source Models: Cost & Risk Breakdown
- Self-Hosted AI for Construction Firms: Architecture, Costs, and Compliance in 2025
- The Evaluation Framework We Use When a Client Asks Us Which Agent Stack to Build On
- Phi-4 vs Gemma 3 vs Mistral Small: A Practical Benchmark for the Enterprise Use Cases That Actually Matter







Leave a Reply