
LLM-Based Document Processing vs Traditional OCR: When Each Actually Belongs in Your Stack
Huzefa Motiwala May 12, 2026
Need to process documents quickly and accurately? The choice between OCR and LLM-based tools depends on your needs.
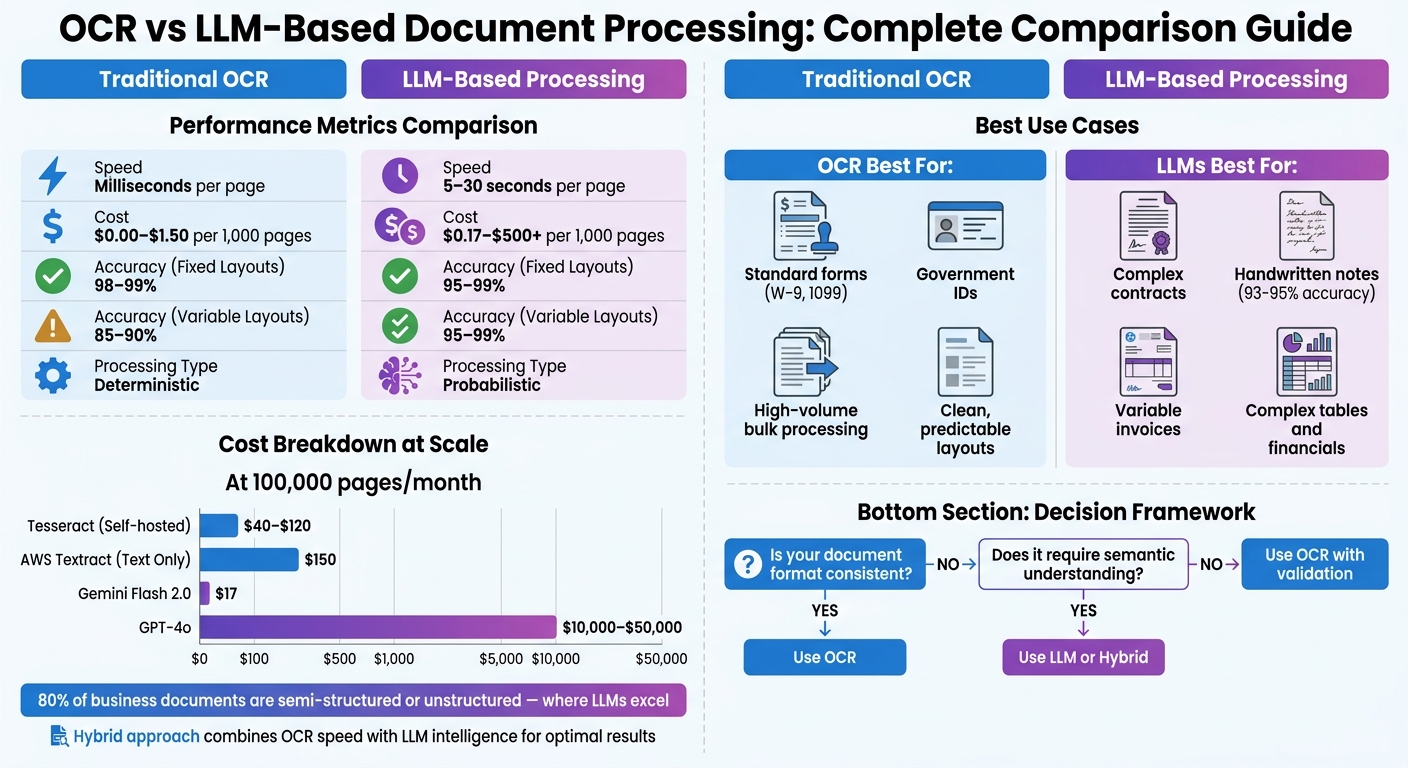
- OCR is great for high-volume, consistent layouts like forms or IDs. It’s fast (milliseconds per page), affordable (from $0.00 to $1.50 per 1,000 pages), and reliable for fixed formats.
- LLMs, like GPT-4o or Gemini Flash 2.0, excel at handling complex, unstructured documents such as contracts or handwritten notes. They interpret context and meaning but are slower (5–30 seconds per page) and cost more ($0.17 to $500+ per 1,000 pages).
What’s the best approach? Use OCR for structured, predictable documents and LLMs for variable, complex ones. Or combine both in a hybrid system for cost-effective, accurate results.
Quick Comparison
| Feature | OCR | LLM-Based Processing |
|---|---|---|
| Speed | Milliseconds per page | 5–30 seconds per page |
| Cost (1,000 pages) | $0.00–$1.50 | $0.17–$500+ |
| Accuracy (Fixed Layouts) | 98–99% | 95–99% |
| Accuracy (Variable Layouts) | 85–90% | 95–99% |
| Best for | Standard forms, IDs | Complex layouts, handwriting |
Choose the right tool – or a hybrid approach – based on your documents’ complexity, volume, and budget.
OCR vs LLM Document Processing: Speed, Cost, and Accuracy Comparison
The Sweet Spot Between OCR and LLMs | Kasey Roh on Fixing Document AI
sbb-itb-51b9a02
When to Use Traditional OCR vs LLM-Based Processing
Choosing between traditional OCR and LLM-based processing isn’t about picking one over the other – it’s about using the right tool for the job based on your document type and business needs.
Traditional OCR shines with structured, high-volume documents. Think of standardized forms like W-9s, 1099s, utility bills, or government IDs where the layout is consistent. OCR systems can hit 99% accuracy on these fixed formats [5][3], processing pages in just 50–200 milliseconds locally (using tools like Tesseract) or 1–3 seconds with AWS Textract [2]. Since OCR delivers the same output for the same input every time, it’s ideal for compliance-heavy industries like finance or healthcare. As Talal Bazerbachi, Founder of Parsli, explains:
Traditional OCR gives you the same output for the same input, every time.
OCR also scales well for large volumes at a low cost – about $1.50 per 1,000 pages with AWS Textract [2].
LLMs, on the other hand, are built for unstructured or variable documents that require deeper understanding. Examples include medical records, legal contracts, and invoices with dozens of layouts. Instead of just reading characters, LLMs interpret the meaning behind the text [10]. They handle challenges like degraded scans, handwriting (achieving 93–95% accuracy on handwriting benchmarks [2]), and complex tables that would overwhelm rule-based systems. For instance, in a study of 500 invoices, Gemini 2.5 Pro achieved 96.50% accuracy on clean invoices and 92.71% on scanned documents, all without any template setup [4]. However, this comes with trade-offs: processing times range from 5–30 seconds per page, and costs can climb to $100–$500+ per 1,000 pages with GPT-4o [2].
When deciding between the two, consider how speed and error tolerance factor into your workflow. For workflows that demand sub-second speed and near-zero error rates – where even minor mistakes could cause major issues – OCR is often the go-to option [12]. But if your document formats change frequently or require understanding relationships between data points, like cross-referencing an invoice with a purchase order, LLMs deliver the contextual reasoning that OCR cannot. Essentially, OCR answers "where is the text" while LLMs answer "what does the text mean" [2].
Rather than viewing these technologies as competitors, think of them as complementary. OCR works best for standardized layouts and high-volume tasks, while LLMs handle variable formats and semantic challenges. Hybrid approaches are increasingly popular – using OCR for quick, cost-effective text extraction on clean documents and delegating more complex or low-confidence sections to LLMs. This combination balances cost, accuracy, and speed, leveraging the strengths of both technologies [2][3].
Cost Analysis by Document Volume
Understanding the costs associated with processing documents at different volumes highlights the growing divide between traditional OCR systems and LLM-based solutions as volumes increase.
Tesseract, being open-source, has no licensing fees, with costs limited to compute resources. For instance, running it on a 1-vCPU cloud instance (handling about 10 pages per minute) costs approximately $5–$15 per month for 1,000 documents, $10–$30 for 10,000 documents, and $40–$120 for 100,000 documents [13]. On the other hand, AWS Textract follows a straightforward per-page pricing model: basic text detection costs $1.50 per 1,000 pages, while extracting forms and tables ranges from $15 to $65 per 1,000 pages [2][13]. At a volume of 100,000 documents per month, this translates to $150 for basic text extraction or $1,500–$6,500 for structured data extraction.
LLM-based systems operate differently, pricing based on token usage rather than documents. The Mindee team emphasizes:
LLMs scale per token, not per document. Multiply that by thousands of documents processed daily and you’ve created a massive cost center [6].
For example, processing a single multi-page contract might consume over 20,000 tokens, leading to costs ranging from $0.20–$1.00+ per document. GPT-4o typically charges $0.10–$0.50+ per page, meaning that handling 100,000 documents could cost between $10,000 and $50,000 per month [2][6].
A major shift occurred in 2026 with the introduction of Gemini Flash 2.0, which redefined cost expectations. Talal Bazerbachi, Founder of Parsli, commented:
Gemini Flash 2.0 broke the cost curve. At roughly $0.17 per 1,000 pages, it’s cheaper than Textract’s basic text extraction while delivering multimodal understanding [2].
At this rate, 6,000 pages can be processed for just $1 [3]. This means costs of $0.17 for 1,000 documents, $1.70 for 10,000, and $17 for 100,000, making it not only cheaper than basic OCR but also capable of providing semantic understanding.
| System | Per-Page Cost | 1,000 Pages/Mo | 10,000 Pages/Mo | 100,000 Pages/Mo |
|---|---|---|---|---|
| Tesseract (Self-hosted) | ~$0.00 (compute only) | $5–$15 | $10–$30 | $40–$120 |
| AWS Textract (Text Only) | $0.0015 | $1.50 | $15.00 | $150.00 |
| AWS Textract (Forms/Tables) | $0.015–$0.065 | $15–$65 | $150–$650 | $1,500–$6,500 |
| GPT-4o (LLM) | $0.10–$0.50 | $100–$500 | $1,000–$5,000 | $10,000–$50,000 |
| Gemini Flash 2.0 (LLM) | $0.00017 | $0.17 | $1.70 | $17.00 |
The data reveals a clear trend: traditional OCR remains the most affordable choice for high-volume structured documents. However, systems like Gemini Flash 2.0 are challenging the status quo by offering intelligent data extraction at costs that rival or even undercut basic OCR [2][3]. This sets the stage for considering how accuracy and compliance might influence your ultimate decision.
Accuracy and Compliance Factors
The accuracy of document processing tools depends heavily on the type of document being analyzed. For instance, traditional OCR systems perform exceptionally well on clean, fixed-layout forms like W-9s or standardized invoices, achieving up to 99% accuracy in such cases [4]. However, their performance drops significantly – down to 80–85% – when dealing with degraded scans or documents with variable layouts [2]. On the other hand, LLM-based methods show better resilience in such scenarios, maintaining 90–94% accuracy on poor-quality scans. Gemini 2.5 Pro, for example, achieves 94% accuracy on scanned invoices, outperforming AWS Textract, which delivers 82% in similar conditions [2].
When it comes to handwriting recognition, the gap widens further. Traditional OCR systems often falter with cursive text [2][10], while modern LLMs like GPT-5 and Gemini 2.5 Pro achieve 93–95% accuracy on handwriting benchmarks [2]. For high-quality digital PDFs, the performance across tools becomes more comparable. GPT-4o leads with 98% accuracy, followed by Claude 3.5 Sonnet at 97%, and AWS Textract at 95%+ [2]. While these differences in accuracy are notable, they’re only part of the equation – compliance in regulated industries is just as important.
Compliance Challenges in Regulated Environments
Accuracy alone doesn’t guarantee success, particularly in industries like finance or healthcare, where compliance is critical. Traditional OCR systems are deterministic, meaning the same input always yields the same output. This predictability makes them easier to audit and validate [2][14]. In contrast, LLMs are probabilistic, which means their outputs can vary with each run. This variability introduces risks, especially when handling sensitive documents, as LLMs can generate incorrect or fabricated content – often referred to as "hallucination" – at rates of 20–30% [1].
To address these risks, experts recommend integrating a deterministic validation layer after LLM extraction. Pratik Moitra, Founder of Onezipp, explains [4]:
The solution [to hallucination] is a deterministic validation layer: a separate computational step applied after LLM extraction that performs mathematical verification independent of the language model.
This validation step typically involves tools like Python scripts or predefined business rules to ensure accuracy. For example, it might verify that line items add up correctly or that extracted dates fall within expected ranges. This approach helps balance the high accuracy of LLMs with the need for auditability in sensitive environments.
Maya Chen, Senior Strategist at OCRDirect, underscores the importance of reliability in these settings:
In sensitive document AI, the best solution consistently demonstrates auditability and reliability. It is the one that can prove, page by page, that it handled PHI safely [9].
Striking a balance between accuracy and compliance is crucial for organizations operating in regulated industries. By combining the strengths of LLMs with robust validation mechanisms, businesses can achieve both precision and reliability in their document processing workflows.
Hybrid Architectures: Using OCR and LLMs Together
Hybrid architectures provide a practical way to balance accuracy and cost for enterprise workflows by combining the strengths of OCR and LLMs.
This approach uses OCR for fast, precise text extraction and pairs it with LLMs for their advanced contextual understanding. Together, they process documents more efficiently and accurately than either technology could on its own.
A typical hybrid pipeline includes four steps: preprocessing (cleaning and normalizing images), OCR extraction (extracting raw text and coordinates), LLM enhancement (mapping fields and structuring data semantically), and deterministic validation (ensuring accuracy in math and logic) [4][18]. This layered process compensates for the limitations of each technology. As Ståle Zerener, Machine Learning Engineer at Cradl AI, explains:
Relying on a dedicated OCR engine for text recognition and using LLMs for interpretation is a lot safer than depending on an LLM alone [7].
This setup integrates smoothly into broader document processing workflows, delivering significant performance improvements.
For instance, hybrid table-based extraction methods can achieve a 54x speedup compared to using multimodal LLMs alone for image-based documents. They maintain F1=1.0 accuracy with an average latency of just 0.97 seconds [15][17]. The key is limiting the LLM to tasks like identifying coordinates and regions, while rule-based parsers handle the actual content extraction. This division of labor streamlines the process and boosts efficiency [15].
Cost savings are another major advantage. Hybrid pipelines significantly reduce token usage compared to full multimodal LLM processing. For example, Gemini Flash 2.0 can process data from 6,000 pages for about $1 in a hybrid setup [3]. Additionally, by anchoring text recognition to the OCR engine, the system avoids hallucination risks, ensuring the LLM doesn’t misinterpret ambiguous characters [7].
Modern hybrid systems also incorporate intelligent routing layers that classify documents before processing. These layers determine whether a document is a born-digital PDF or a scanned file, directing it to the most efficient path. This avoids unnecessary OCR for clean digital files while ensuring scanned documents receive appropriate preprocessing [16]. This format-aware routing optimizes both speed and accuracy, making these systems adaptable to a wide range of document types and needs.
Pros and Cons
Traditional OCR and LLM-based processing each bring distinct advantages to the table, making them suitable for different types of workflows. Choosing the right approach means understanding these trade-offs and aligning them with your specific needs.
Let’s break down the strengths and limitations of each method.
Traditional OCR is a go-to solution for speed and cost efficiency when dealing with standardized documents. It can process pages in milliseconds to a few seconds, achieving 98–99% accuracy on fixed, printed text [8][10]. Its deterministic nature ensures consistent results, which is crucial for compliance-heavy tasks. However, OCR struggles with documents that deviate from fixed templates, as it relies heavily on rigid layouts. As Florin Iten, Co-Founder of Dokumentas, aptly explains:
OCR answers the question ‘What characters are on this page?’ – but not ‘What does this document mean?’ [10]
LLM-based processing, on the other hand, shines when working with variable layouts and extracting deeper meaning. It adapts seamlessly to new formats and understands semantic relationships, such as recognizing that "Total" and "Amount Due" convey the same information, even if positioned differently [1][10]. LLMs outperform traditional OCR by 10–15 percentage points on scanned documents and can cut processing times by 50–70% in end-to-end workflows [2][8]. However, there are trade-offs: higher latency (5–30 seconds per page), occasional errors like hallucinations (plausible but incorrect outputs), and higher costs for advanced models. That said, tools like Gemini Flash 2.0 have made pricing more competitive, offering services for as little as $0.17 per 1,000 pages [2][3].
Here’s a quick comparison to summarize these differences:
| Feature | Traditional OCR | LLM-Based Processing |
|---|---|---|
| Speed | Fast (<1 sec/page) | Slower (5–30 sec/page) |
| Accuracy (Fixed Layouts) | 98–99% | 95–99% |
| Accuracy (Variable Layouts) | 85–90% | 95–99% |
| Cost per 1,000 Pages | $0.00–$1.50 | $0.17–$500+ (depends on model) |
| Layout Handling | Rigid (template-dependent) | Adaptive |
| Output Type | Raw text/coordinates | Structured JSON/CSV |
| Error Type | Obvious (e.g., missing text) | Subtle (e.g., hallucinations) |
| Reliability | Deterministic | Probabilistic |
The most important takeaway? 80% of business documents are semi-structured or unstructured, where traditional OCR often falls short [10]. For tasks involving high-volume standardized forms like W-9s or tax returns, OCR remains a practical choice. But when dealing with diverse invoices or documents requiring semantic understanding, LLM-based processing is the better fit. The decision matrix in the next section will guide you in applying these trade-offs to your specific needs.
Conclusion
When deciding on a document processing method, it’s important to weigh factors like format, document volume, accuracy requirements, and budget. Traditional OCR works well for high-volume, fixed-format documents where speed and cost are priorities. On the other hand, LLMs shine when dealing with variable layouts, handwritten content, or extracting deeper semantic meaning.
By 2026, most enterprise workflows are expected to benefit from a hybrid approach. This setup uses OCR for quick and straightforward extraction while reserving LLMs for more complex or ambiguous tasks. The result? A cost-efficient solution that typically pays off within 3–6 months [10].
Here’s a quick decision matrix to help match document types with the best processing method:
| Document Type | Recommended Approach | Key Reason |
|---|---|---|
| Standard Forms (W-9, 1099) | Traditional OCR | Consistent layout and predictable output [3] |
| Variable Invoices/Receipts | Hybrid (OCR + LLM) | Adapts to format changes without templates [2][4] |
| Legal Contracts | LLM (Premium) | Requires clause extraction and reasoning [3][20] |
| Handwritten Notes | LLM | Contextual understanding (93–95% accuracy) [2] |
| High-Volume Bulk (Clean) | Traditional OCR | Lowest cost and highest throughput [2][11] |
| Complex Tables/Financials | LLM | Handles nested headers and merged cells [2] |
| ID Documents | Traditional OCR | Standardized format and privacy concerns [3] |
For clean, high-volume documents, start with cost-effective tools like self-hosted Tesseract, which offers near-zero cost. Save premium models – such as GPT-4o, which can cost $100–$500+ per 1,000 pages [2] – for edge cases where complexity justifies the investment. As Doug Lawrence, CTO of CLARA Analytics, aptly notes:
The value is not in transcribing a PDF. That is commodity work. The value is in finding the physician’s note on page 47 that changes the trajectory of a claim [19].
Ultimately, the key to success lies in building a smart pipeline that combines the strengths of OCR and LLM tools. By aligning the technology with your specific document needs, you can boost efficiency, ensure compliance, and make the most out of your resources.
FAQs
How do I decide between OCR and an LLM for a document type?
The right tool depends on the type of document you’re working with. Traditional OCR shines when dealing with highly structured, fixed-format documents – think invoices or forms. It’s fast, cost-effective, and can hit nearly 99% accuracy when layouts are consistent.
On the other hand, LLMs are better suited for unstructured or variable formats, like contracts or emails. They bring a deeper level of context and reasoning to the table, making sense of more complex or less predictable content.
For many cases, a hybrid approach works best. OCR handles the initial data extraction efficiently, while LLMs step in to interpret and refine the information. This combination strikes a balance between accuracy and cost.
When does a hybrid OCR+LLM pipeline pay off?
A combined OCR (Optical Character Recognition) + LLM (Large Language Model) pipeline works best for handling complex, unstructured, or repetitive documents – the kind that often trip up traditional OCR systems. Here’s how it works: OCR takes care of the initial text extraction, doing so quickly and efficiently. Then, LLMs step in to interpret and organize the extracted data, minimizing errors along the way.
This setup shines in scenarios with diverse document formats, high accuracy requirements, or tasks involving inconsistent layouts (like vendor-specific templates). By pairing OCR’s speed with the reasoning power of LLMs, it’s particularly effective for large-scale operations where precision and adaptability are critical.
How do I prevent LLM hallucinations in regulated workflows?
To tackle hallucinations in large language models (LLMs) within regulated workflows, it’s crucial to focus on strategies that enhance the reliability and accuracy of their outputs. Here are some key approaches:
- Incorporate external knowledge: Use retrieval methods, such as Retrieval-Augmented Generation (RAG), to provide the model with verified, up-to-date information.
- Set confidence thresholds: Filter out results that fall below a defined confidence level to reduce the likelihood of unreliable outputs.
- Human oversight: For critical or sensitive information, ensure that human experts review and validate the outputs.
Beyond these, strict fact-checking and governance protocols are essential. These measures help maintain compliance with regulations and minimize risks, especially in workflows where accuracy is non-negotiable.







Leave a Reply