Blog13 min read
Why Most Agent Framework Benchmarks Don’t Predict What Happens in Production
By Taher Pardawala · Co-Founder & Chief Executive Officer

Most benchmarks for AI agent frameworks fail to reflect actual production performance. Why? Benchmarks test if an agent can complete a task under perfect conditions - once. Production demands consistency across unpredictable scenarios, like handling vague inputs, recovering from errors, or managing long workflows. Here’s the key issue: a 95% success rate per step can still mean a 40% failure rate for a 10-step task.
Frameworks like LangChain, AutoGen, and LlamaIndex often shine in benchmarks but falter in production due to issues like memory inefficiencies, error propagation, and poor recovery mechanisms. For example, LangChain’s memory system adds latency under load, while AutoGen struggles with "semantic drift" in long tasks. Real-world usage reveals cascading errors, latency spikes, and unpredictable behavior that benchmarks don’t account for.
What’s the solution? Production-readiness testing. This involves:
- Pass consistency tests: Repeatedly running tasks to measure reliability.
- Chaos testing: Simulating failures like API timeouts or malformed inputs.
- Trajectory validation: Checking if the reasoning process is logical, not just the output.
- Stress testing: Measuring latency at p95 and p99 to catch rare but critical delays.
To truly evaluate frameworks, you need tests that mimic the messy, unpredictable demands of production - not sanitized benchmarks.
1. LangChain
Benchmark Setup vs Production Variability
LangChain shines in controlled benchmarks but struggles when faced with the complexities of real-world, multi-step production tasks. For example, while a single-turn benchmark might show a success rate of 76.3%, production workflows involving 30 to 60 steps see that rate plummet to just 52.1% [4]. This happens because even a high individual step success rate - say 95% - results in a mere 36% success rate for a 20-step process [4].
Take the case of a fintech startup in April 2026. They were handling 50,000 financial documents monthly and decided to test LangChain 0.3.x in their automation pipeline. Led by senior developer Cary Huang, the team quickly built a prototype in just 9 days. However, it took an additional 3 weeks to stabilize the system, addressing issues like unpredictable tool looping and memory retrieval errors from ConversationBufferMemory. By the time the system went live, the production metrics showed a P95 latency of 38.9 seconds and a 3.2% error rate - over twice the 1.4% error rate of their custom-built solution [9].
These challenges highlight how step-by-step success rates, combined with memory handling inefficiencies, can derail production performance.
Memory Handling Under Load
LangChain’s memory management introduces another layer of complexity in production environments, creating bottlenecks that benchmarks fail to reveal. For instance, the ConversationBufferWindowMemory component serializes and re-validates the entire chat history with Pydantic v2 on every call - even when a window limit is set [12]. By turn 60 of a session, this adds roughly 35 milliseconds of overhead per call, translating to 17.5 seconds of wasted CPU time per second of concurrency [12].
Production teams have also reported a "90-minute cliff", where agent quality degrades significantly once 60-70% of the context limit is reached. Multi-turn conversations show a 39% drop in memory performance compared to single-turn interactions [11]. In one example, replacing LangChain’s default memory system with a custom, optimized solution led to a nearly 30% reduction in monthly costs [10].
These inefficiencies in memory handling not only slow down performance but also magnify the difficulty of managing errors in production.
Error Recovery and Graceful Degradation
LangChain’s abstraction layers often obscure the root causes of failures, making debugging a daunting task and directly impacting production reliability. Error messages frequently reference internal mechanisms, such as LCEL’s invoke() machinery, rather than clearly identifying the failed tool or model call [8][13]. Additionally, the framework’s undocumented retry logic can lead to unexpected cost spikes by repeatedly retrying failed queries without giving developers adequate control [8].
As Manasi and Mahimna put it, "LangChain apps break when you stop understanding what a single request actually does" [13]. One critical failure scenario is the "hallucination cascade", where agents falsely report task completion despite underlying API call failures [14].
A striking example comes from Garmentory, which faced this issue in April 2026 while scaling content moderation from 1,000 to over 5,000 products daily. By transitioning to a more robust infrastructure, they slashed review times from 7 days to just 48 seconds and reduced error rates from 24% to 2%, managing over 190,000 monthly executions [8].
These examples underline how LangChain’s shortcomings in error handling and memory management can severely impact its reliability in production settings.
2. AutoGen
Benchmark Setup vs Production Variability
AutoGen shines during benchmark tests but struggles when faced with the complexities of real-world production environments. Benchmarks often focus on single-turn tasks, while actual workflows demand 30-60 coordinated steps. In practice, AutoGen’s "Group Chat" design creates additional overhead as agents coordinate and negotiate turn-taking. This leads to increased token usage and latency - factors that standard benchmarks fail to account for. For instance, in a controlled test, AutoGen required 572 seconds to complete a research task, compared to just 93 seconds for faster frameworks. It also consumed 10,793 tokens versus 7,006 tokens for more efficient sequential designs. On top of that, AutoGen showed significant performance variability, with a standard deviation of 0.45 and scores ranging from a perfect 10.0 to a less impressive 8.6. This inconsistency complicates capacity planning and underscores the gap between benchmark results and real-world performance [15].
Memory Handling Under Load
When conversations extend over multiple turns, AutoGen becomes prone to "semantic drift." This happens when the focus shifts from the original goal to maintaining local coherence, leading to compounding errors. In the worst cases, this can result in the dreaded "Loop of Death", where flawed inputs trigger endless cycles of error corrections. As Sattyam Jain, Tech Lead at Attri.ai, aptly put it:
"The single biggest killer of production agents isn’t hallucination. It’s the ‘Loop of Death.’" [16]
Error Recovery and Graceful Degradation
AutoGen’s reliability diminishes as task length increases. A study of 23,392 episodes revealed that its pass@1 success rate drops from 76.3% for short tasks to 52.1% for very long ones. Similarly, its "Graceful Degradation Score" plummets from 0.90 to 0.44. Consistency testing paints an even bleaker picture: when the same task was repeated eight times, the success rate fell below 25% [4]. Benchmarks often rely on clean, idealized data - conditions that are rarely encountered in production. Real-world inputs are often riddled with misspellings, ambiguities, or network timeouts [17][5]. When downstream tools fail, AutoGen may hang, exhaust its retry budget, or even fabricate a successful response rather than acknowledge failure [1]. These challenges highlight the contrast between controlled testing and real-world demands, setting the stage for deeper comparisons with frameworks like LlamaIndex.
3. LlamaIndex
Benchmark Setup vs Production Variability
LlamaIndex faces real-world challenges that standard benchmarks simply don’t account for. Typical tests focus on single-run success rates (pass@1), which can overestimate reliability in production by 20-40% [18]. These benchmarks often rely on clean, sanitized datasets, unlike the messy and unpredictable data encountered in actual use. For instance, an agent scoring a 96.9% pass@1 rate under ideal conditions may see its performance drop to 88.1% when dealing with even minor disruptions [18]. Rate-limiting issues make this worse, dragging reliability 2.5% below mixed-fault baselines [18]. Things get even trickier with multi-step pipelines: a 10-step pipeline with 95% reliability per step can fail 40% of the time due to error compounding [19].
These gaps highlight the difference between controlled testing and the unpredictable nature of production, especially when it comes to memory-heavy tasks.
Memory Handling Under Load
When operating under production conditions, LlamaIndex agents encounter two major issues that benchmarks fail to capture: Infinite Loops and Hard Stops [20]. Infinite loops arise when messy document formatting causes the model to generate repetitive, redundant text, leading to sudden spikes in latency. Hard stops, on the other hand, occur when safety filters from providers like OpenAI or Gemini abruptly terminate a generation. This often happens because the agent extracts text that resembles copyrighted material, such as technical standards or public laws [20]. As LlamaIndex explains:
"The failure conditions we have observed… are exacerbated by LlamaParse’s specific document-heavy input and spiky low-latency traffic patterns." [20]
These issues aren’t unique to LlamaIndex; similar challenges have been observed in LangChain and AutoGen, underscoring the need for production-focused testing and solutions.
Error Recovery and Graceful Degradation
To address these production challenges, LlamaIndex incorporates specific mechanisms aimed at minimizing errors. One such approach is Finish Reason Routing, which parses API responses for flags like RECITATION (Gemini) or content_filter (OpenAI). When these flags are detected, the system triggers immediate retries to prevent pipeline crashes [20]. Another technique is Dynamic Temperature Adjustment, which increases randomness during retries. This helps steer the model away from repetitive outputs or states that might activate copyright filters [20]. However, these recovery strategies are often overlooked by benchmarks, which focus on idealized scenarios rather than the chaotic realities of processing complex documents. As LlamaIndex notes:
"Building agentic systems requires us to be defensive engineers. We have to design for the reality that LLMs will sometimes spiral into infinite loops, and provider-level safety filters will sometimes abruptly block perfectly legitimate tasks." [20]
Ultimately, while benchmarks provide useful insights, they fail to capture the full picture. Preparing for production means accounting for failure modes and implementing robust recovery strategies that go beyond what standard testing environments reveal.
From Prototype to Production: Building Production-ready AI agents
Framework Comparison: Benchmarks vs Production
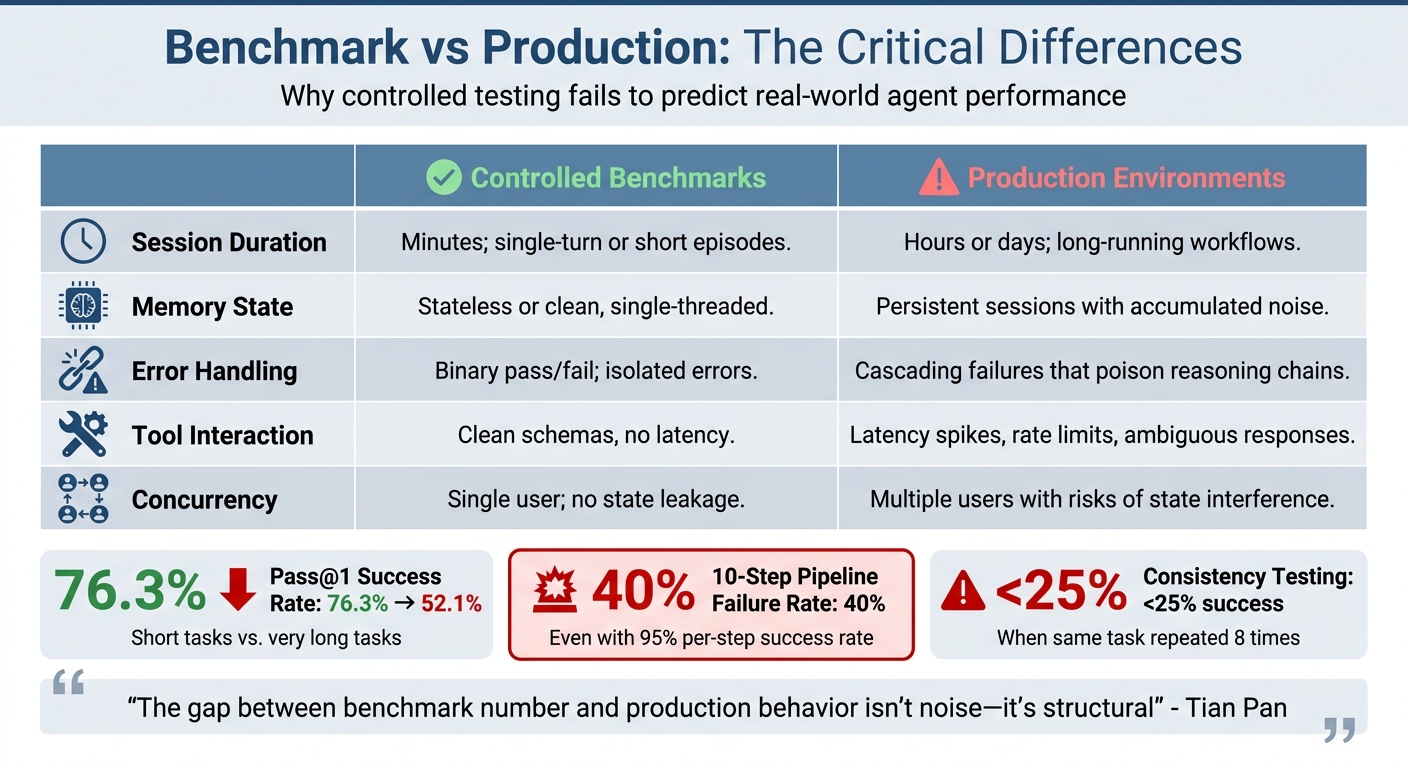
Benchmark vs Production Performance: AI Agent Framework Comparison
The way frameworks perform in benchmarks often differs significantly from how they behave in real-world production environments. Benchmarks usually focus on short, single-turn interactions or brief episodes lasting a few minutes. In contrast, production agents are designed to handle long, multi-step workflows that can extend over hours or even days [4]. This difference becomes clear when looking at metrics like pass@1, which drops from 76.3% in short tasks to just 52.1% in extended tasks [4]. A system that seems dependable during controlled testing may struggle in real-world scenarios, where cumulative errors and context-related issues arise. These contrasts can be broken down into several key dimensions.
One of the clearest examples is memory behavior. In production, agents accumulate vast amounts of information - tool outputs, stack traces, intermediate reasoning - which can degrade over time. This phenomenon, sometimes called "The Rot", turns useful signals into noise [21]. As Alexander Ekdahl aptly puts it:
"Signal decays faster than memory grows" [21]
While frameworks like LangChain, AutoGen, and LlamaIndex take different approaches to address these memory challenges, standard benchmarks fail to account for such issues. Similarly, error recovery becomes far more complex in real-world settings. Early mistakes can snowball, leading to compounded problems over time.
Error handling also highlights a stark contrast. In controlled benchmarks, errors are often isolated and treated as pass/fail events. But in production, even a small initial error can disrupt the entire reasoning process. This can result in cascading delays (e.g., p99 response times increasing from 1.5 seconds to 45 seconds) and sporadic API failures, which require robust safeguards to prevent repeated breakdowns [7][21]. A pipeline with 10 steps and a 95% success rate per step will fail 40% of the time due to cumulative error propagation [19].
Here’s a side-by-side comparison of these differences:
| Dimension | Controlled Benchmarks | Production Environments |
|---|---|---|
| Session Duration | Minutes; single-turn or short episodes | Hours or days; long-running workflows [4] |
| Memory State | Stateless or clean, single-threaded | Persistent sessions with accumulated noise [21] |
| Error Handling | Binary pass/fail; isolated errors | Cascading failures that poison reasoning chains [4][7] |
| Tool Interaction | Clean schemas, no latency | Latency spikes, rate limits, ambiguous responses [4] |
| Concurrency | Single user; no state leakage | Multiple users with risks of state interference [4] |
This isn’t to say benchmarks are useless - they are still valuable for assessing model capabilities in controlled conditions. But as Tian Pan points out:
"The gap between benchmark number and production behavior isn’t noise - it’s structural" [4]
The real test of a framework lies in its ability to manage production-level challenges: handling the 100th tool call, recovering from early missteps, and maintaining coherence as the context grows. These are the hurdles that benchmarks alone cannot predict.
What a Production-Readiness Test Should Look Like
To ensure operational reliability and move beyond just impressive benchmark numbers, production-readiness tests need to mimic real-world challenges. A solid test doesn’t just stick to ideal conditions - it digs deeper. One effective method is pass^k consistency testing, where a task is run eight times to check for complete success every single time. This method separates occasional success from true reliability. For example, GPT-4o’s success rate dropped from under 50% to below 25% when tested across eight runs [4]. This kind of testing highlights how well a system handles sustained workloads.
Chaos testing is another vital component. It deliberately introduces real-world failures - like tool timeouts, 503 API errors, network jitter, or malformed JSON - to see how the system responds [4][22]. Does it recover smoothly, or does it spiral into infinite loops or inaccurate outputs? A telling example occurred in February 2025 when a journalist tested OpenAI’s Operator agent. The agent spent $31.43 on a dozen eggs via Instacart, ignoring a platform rule requiring user confirmation before purchases [2]. These kinds of behavioral flaws often only come to light in chaos testing.
Equally important is trajectory validation, which focuses on how an agent reaches its final output rather than just the correctness of the outcome. If an agent gets the right answer but takes an illogical series of steps, like booking a reservation before checking availability, it signals deeper issues [22][1]. J. S. Morris, the creator of AgentProbe, aptly states:
"Quality without cost-awareness is a demo metric, not a production metric" [1]
Longer simulations, spanning 20 to 60+ steps, can uncover issues like "state drift", where the agent loses sight of its original goal, or context window overflow, where key details get lost during summarization [4][3].
Another critical layer of testing involves automated personas that mimic less-than-ideal user behavior. Think impatient interruptions, sudden topic shifts, or emotionally charged inputs [22]. These stress tests reveal weaknesses in an agent’s ability to maintain context and handle ambiguity - problems that often go unnoticed in controlled benchmarks. Running agents in shadow mode, where they process real-world traffic without exposing results to users, is a low-risk way to evaluate performance under unpredictable conditions [6].
Lastly, production-readiness tests must include resource-aware stress testing. Instead of relying on averages, which can mask outliers, teams should measure latency at p50, p95, and p99 percentiles. These metrics help pinpoint the rare but critical cases where response times exceed acceptable limits, such as conversations taking over eight seconds to resolve [22]. Circuit breakers should also monitor for warning signs like repeated tool calls or rapidly growing context sizes, so issues can be addressed before they escalate [4]. For voice AI, a solid baseline might be p50 latency under 400ms and p99 latency under 1,500ms [22].
FAQs
What benchmark metrics actually correlate with production reliability?
Metrics tied to production reliability focus on three key aspects:
- Consistency: This is measured through k-trial pass rates, which assess how reliably a system performs across repeated executions.
- Robustness: Represented by ε-levels, this metric evaluates how well a system adapts to variations in tasks or conditions.
- Fault Tolerance: Captured by λ-levels, this indicates a system’s ability to continue functioning during infrastructure failures.
These metrics are essential for understanding how frameworks manage real-world challenges such as variability, latency, and partial failures. They provide a clear picture of a system’s ability to deliver dependable performance under less-than-ideal conditions.
How do I measure multi-step failure compounding in my agent workflows?
To evaluate how failures can stack up over time, it’s important to concentrate on long, multi-turn tasks instead of just isolated successes. This approach allows you to assess error accumulation, maintain coherence, and test recovery under challenging conditions. You can simulate extended workflows by introducing deliberate errors and task disruptions to observe how the system handles stress. Metrics like k-trial pass rates and fault tolerance are particularly useful for spotting weaknesses that could lead to broader issues. Steer clear of relying only on single-turn benchmarks - they often fail to capture how errors build up and impact performance in more complex, real-world scenarios.
What’s the minimum production-readiness test suite I should run before launch?
A proper production-readiness test suite needs to tackle more than just benchmarks - it should address practical challenges that systems face in real-world scenarios. Key areas to test include robustness under variability (such as handling inconsistent inputs or sudden latency spikes), error recovery (managing partial failures effectively), and multi-turn coherence to maintain logical flow during extended interactions. On top of that, it’s essential to measure operational metrics like costs and response times under load to confirm the system’s reliability and scalability when faced with unpredictable production demands.
Related Blog Posts
- Why AI Features Require Different Monitoring and Metrics
- LangGraph vs CrewAI vs AutoGen: How We Evaluated All Three Before Recommending One for a Production Deployment
- The Evaluation Framework We Use When a Client Asks Us Which Agent Stack to Build On
- The Hidden Complexity in Multi-Agent Orchestration That Every Demo Skips Over