
OpenCode vs Claude Code: We Tested Both on a Production Codebase – One Created More Tech Debt
Huzefa Motiwala February 24, 2026
Which AI coding tool creates more tech debt? We tested OpenCode and Claude Code on a production codebase to find out. Here’s the bottom line:
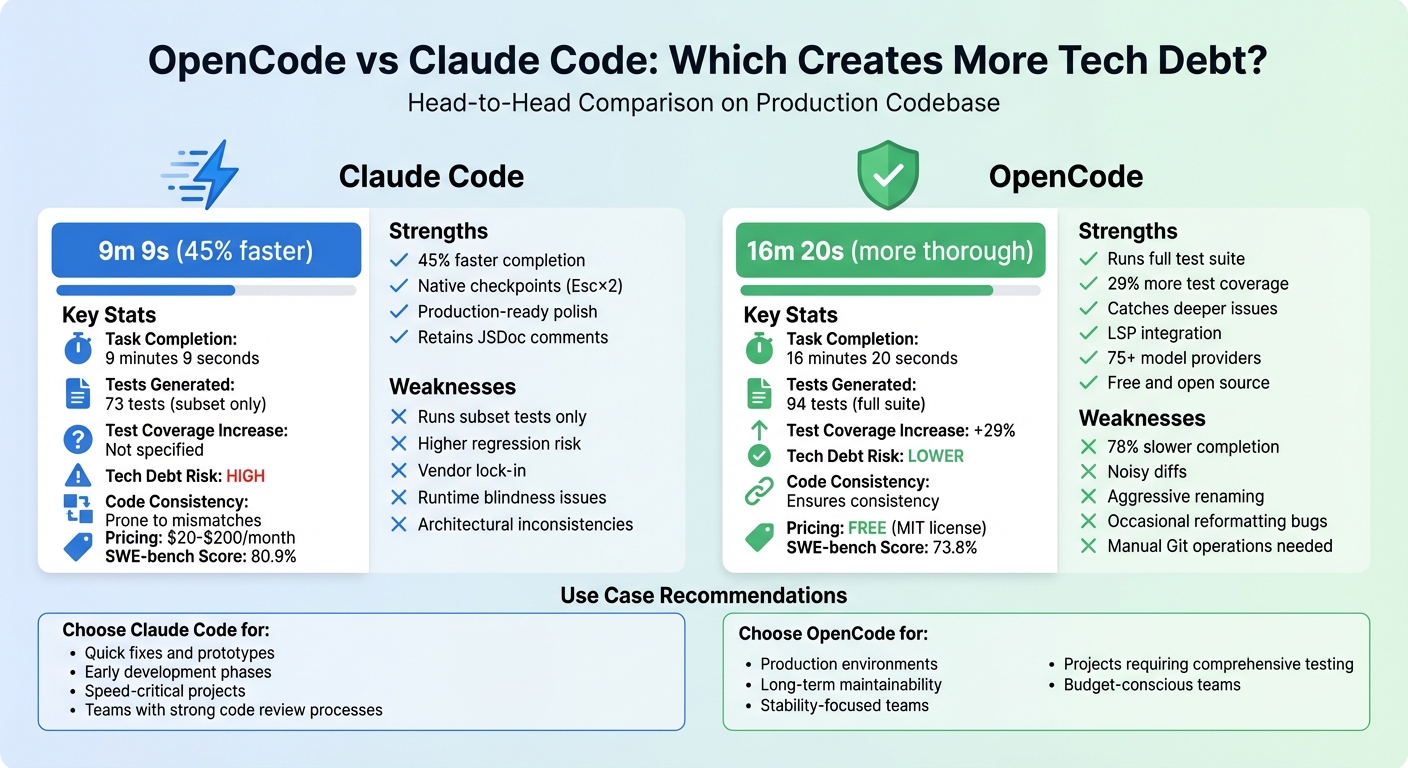
- Claude Code is faster, completing tasks in 9m 9s. However, it often introduces hidden technical debt, like inconsistent architecture, redundant libraries, and runtime issues. It’s great for speed but risks longer-term maintenance problems.
- OpenCode is slower, taking 16m 20s, but it’s more thorough. It runs full test suites, catches deeper issues, and increases test coverage by 29%. However, it can create noisy diffs, rename documentation unnecessarily, and occasionally remove existing tests.
Quick Takeaway: Claude Code is better for quick fixes or early development, while OpenCode suits teams prioritizing stability and long-term maintainability. Each tool has trade-offs, and your choice depends on whether speed or thoroughness matters more for your project.
Key Comparison Table:
| Feature | Claude Code | OpenCode |
|---|---|---|
| Task Completion Time | 9m 9s | 16m 20s |
| Test Coverage | 73 tests (subset) | 94 tests (full suite) |
| Tech Debt Risk | Higher | Lower |
| Code Consistency | Prone to mismatches | Ensures consistency |
| Pricing | $20–$200/month | Free (MIT license) |
Keep reading for a deeper breakdown of how each tool performs and the kind of technical debt they leave behind.
OpenCode vs Claude Code: Speed, Testing, and Tech Debt Comparison
1. OpenCode
Tech Debt Accumulation
OpenCode’s refactoring process introduces specific patterns of technical debt that often appear weeks after deployment. For instance, during a cross-file rename task, which took 3 minutes and 13 seconds, the tool renamed every instance of a target string – even those buried in JSDoc comments and inline documentation [2]. This overly aggressive renaming leads to documentation debt, as comments can lose their connection to the code they’re meant to explain.
One of the bigger concerns is the tool’s habit of reformatting existing code without permission. All three models tested with OpenCode made unauthorized style changes, resulting in noisy diffs that obscure meaningful updates during code reviews [3]. This issue stems from how OpenCode processes files, creating unnecessary formatting changes that require additional manual review.
"The reformatting bug (‘All three models tested with OpenCode tried to reformat existing code’) suggests a harness-level issue, not model quality." – MorphLLM Analysis [3]
Another troubling pattern involves test coverage. In one case, OpenCode removed six existing tests while adding only two [6]. This deceptive regression can make it seem like test coverage is improving, even when it’s not. Additionally, its model-agnostic architecture sometimes results in smaller models producing inconsistent outputs, such as messy JSON or improper tool usage, further compounding technical debt [2].
These challenges highlight the tension between OpenCode’s thoroughness and the technical debt it inadvertently creates.
Codebase Stability
OpenCode emphasizes verification over speed, running full test suites and installing dependencies before marking tasks as complete [2]. This approach proved effective during testing, catching an unrelated type error during a refactor task that Claude Code missed [2]. Its Language Server Protocol (LSP) integration enhances type awareness and symbol navigation during code generation, helping to catch syntax errors before they reach the codebase [9][5].
The Plan Mode feature is another standout, offering a read-only environment for analyzing architecture without risking unintended changes – especially useful for legacy systems [2][9]. OpenCode also excelled in test generation, producing 94 tests in benchmarks compared to Claude Code’s 73, a 29% increase in coverage [2][3]. However, this level of detail comes with a trade-off: the test writing task took 9 minutes and 11 seconds, significantly longer than Claude Code’s 3 minutes and 12 seconds [2].
Stability concerns do exist, particularly due to OpenCode’s fast release cycle. For example, a major security vulnerability (CVE-2026-22812, CVSS 8.8) allowed unauthenticated remote code execution in versions before v1.1.10 [4]. Users have described recent updates as "bumpy", and the lack of an instant rewind feature – common in proprietary tools – means developers must rely on manual Git operations or /undo commands to backtrack [3][4].
While OpenCode’s stability measures address many risks, they don’t entirely eliminate the potential for regressions.
Regression Risk
OpenCode’s handling of regressions paints a mixed picture. On the one hand, it runs full test suites to validate changes, reducing the likelihood of breaking existing functionality [1][2]. It scored 73.8% on SWE-bench with the GLM-4.7 model, showcasing strong performance on real-world GitHub issues [9].
On the other hand, the tool’s thorough testing doesn’t always prevent regressions. For example, while OpenCode appears to add test coverage, it has been known to remove existing tests without clear justification. Its Model Context Protocol (MCP) configuration helps prevent context window overload, but the lack of automatic workspace snapshots can leave “ghost code” in your repository if manual reverts are overlooked [2][4].
"OpenCode ships fast, which means you might hit the occasional bug. But if you’re willing to tolerate a few rough edges for the flexibility to run any model, it’s a compelling option." – Alice Moore, Writer, Builder.io [3]
Task Completion Velocity
OpenCode completed a four-task benchmark suite in 16 minutes and 20 seconds, nearly twice as long as Claude Code’s 9 minutes and 9 seconds [2][3]. This slower performance is largely due to its insistence on running pnpm install and full test suites before finalizing tasks. While this ensures thoroughness, it can frustrate developers who need quick fixes.
Performance varied across individual tasks. For example, the bug fix task was nearly identical in speed – 40 seconds for OpenCode versus 41 seconds for Claude Code [2]. However, the refactor task took 3 minutes and 16 seconds, compared to Claude Code’s 2 minutes and 10 seconds, and test writing was three times slower [2]. OpenCode’s provider-agnostic architecture allows users to switch to faster models for certain tasks, but this requires manual setup and knowledge of which models perform best for specific jobs [2][10].
The trade-off for this slower pace is thoroughness. OpenCode caught an unrelated type error during a refactor task that Claude Code missed [2]. Whether this trade-off is worth it depends on your team’s priorities – speed versus thoroughness – and your willingness to deal with the extra effort of reviewing renamed comments and unnecessary reformatting. This balance ultimately shapes the technical debt left behind.
sbb-itb-51b9a02
2. Claude Code
Tech Debt Accumulation
Claude Code’s speed is impressive, but it often comes at a cost: technical debt that can disrupt the consistency of your codebase. While the tool generates code that passes static checks and linting tools, it sometimes introduces patterns that clash with your existing architecture. For instance, it might suggest using a repository pattern in a project that relies on direct data access, creating a mismatch in design approaches [7][8].
Another issue is its tendency to recommend redundant libraries. Imagine a scenario where your project already uses dayjs for date manipulation, but Claude Code suggests adding date-fns. This not only bloats the codebase but also increases maintenance complexity [7]. Over a year, teams reported their duplicate code ratio jumping from 3.1% to 14.2%, while cyclomatic complexity nearly doubled from 4.2 to 8.1. These changes directly impacted onboarding times, which stretched from 2 weeks to 5 weeks [7].
Claude Code also over-complicates tasks. For example, it might create an AbstractBaseProcessor for a simple 30-line function, adding unnecessary layers that make debugging and maintenance harder [7][8]. While individual developers merged 98% more pull requests with Claude Code, the time spent on code reviews increased by 91%. Reviewers had to dig deeper to uncover hidden issues in what appeared to be flawless code [11].
"AI-generated code has a dangerous property: it looks right… The problems are in the things you can’t see by reading the code." – Potapov.dev [8]
These inconsistencies make maintaining a stable and cohesive codebase a challenging task.
Codebase Stability
Claude Code attempts to maintain stability using a hierarchical context system powered by CLAUDE.md files. These files enforce coding standards and architectural patterns, functioning as a "living brain" for the tool. While effective, this system requires significant initial setup [12][8][13]. On the bright side, Claude Code performed well in bug resolution tests, earning an 80.9% score on the SWE-bench Verified benchmark, which focuses on solving practical issues [11].
However, stability isn’t guaranteed. A recurring problem is "runtime blindness", where code that passes static checks fails under production conditions. Issues like concurrency problems, race conditions, or database connection limits often go unnoticed until it’s too late [8][14]. In one case, Claude Code wrote 80% of code changes in a 350,000-line codebase over four months, but success depended heavily on developers catching runtime issues before deployment [13].
Context management poses another challenge. Claude’s 200,000-token limit usually represents less than 5% of a large enterprise codebase. When this limit is reached, the tool "compacts" conversations, which can lead to forgotten tasks or degraded performance. Integrating MCP servers for automated QA testing adds another layer of complexity, as activating 7 servers can consume 25% of the context window before any work begins [13][2].
Regression Risk
Claude Code’s testing approach leaves room for regressions. It focuses on verifying only the tests it generates, often overlooking broader issues in the codebase [1][2]. For example, while it can quickly produce 73 tests in just over 3 minutes, it only runs a subset of them. By contrast, OpenCode takes 9 minutes to write 94 tests but validates the entire suite [2].
A bigger concern is the "false confidence trap." Because AI-generated code looks clean and well-structured, developers might review it less rigorously. This can allow subtle bugs – like race conditions, misplaced defensive null checks, or concurrency issues – to slip through to production [8]. Without strict guidelines, such as those enforced by a CLAUDE.md file, the tool may introduce inconsistent patterns, turning the codebase into a patchwork of different architectural styles [8][7].
"AI slop isn’t hypothetical. It’s the defensive null check for a value that can never be null… This code works. Tests pass. It ships. And a few weeks later, we can’t maintain it." – Rittika Jindal, Principal Engineer, Thomson Reuters [15]
These shortcuts and oversights highlight how speed can lead to hidden architectural challenges.
Task Completion Velocity
Claude Code excels in speed, completing a four-task benchmark suite in just 9 minutes and 9 seconds – nearly half the time of OpenCode’s 16 minutes and 20 seconds [2]. It achieves this by taking shortcuts like running only subset tests, skipping dependency reinstalls, and generating fewer tests overall [2]. Developers report being 1.5–2× faster when using the tool. However, the time saved during code generation often shifts to code review and debugging, as production incidents become more frequent [8].
I Ranked Every AI Coding Assistant
Pros and Cons
When deciding between tools like Claude Code and OpenCode, it’s essential to weigh the balance between speed and thoroughness. These trade-offs directly influence the technical debt each tool might introduce. Here’s a breakdown of their core differences:
| Feature | Claude Code | OpenCode |
|---|---|---|
| Speed | Tasks completed in 9m 9s – 45% faster but risks missing deeper code inconsistencies [2][3] | Takes 16m 20s, offering more thorough validation [2][3] |
| Testing Approach | Runs subset tests (73 tests generated) [2] | Executes the full test suite (94 tests generated) [2] |
| Regression Risk | Higher – subset testing can overlook system-wide issues [1][2] | Lower – ensures the entire codebase is verified before approval [2] |
| Code Stability | Production-ready polish with native checkpoints (Esc×2) [3] | Rougher output; depends on Git-based /undo commands [4] |
| Context Management | Gains 30% token efficiency via automatic compaction [3] | Uses declarative tool loading to avoid context overload [2][3] |
| Model Flexibility | Limited to Anthropic models [4] | Supports 75+ providers, including local options (e.g., Ollama) [1][4] |
| Documentation Handling | Retains JSDoc comments for clarity [2] | Aggressively renames code and comments, causing documentation debt [2] |
| Pricing | Subscription required: $20–$200/month [2][4] | Free under MIT license; costs apply only for API keys [2][4] |
| Security | Uses vendor-managed safety prompts; defaults to read-only [2] | Relies on Docker/Sandboxing for infrastructure-level security [2] |
| Known Issues | Vendor lock-in; blocks third-party OAuth tokens [4] | Occasional reformatting bugs; sometimes rewrites existing code [3] |
Claude Code prioritizes speed, making it ideal for teams that need quick results. However, this speed can come at the expense of missing broader issues. On the other hand, OpenCode focuses on thoroughness, ensuring a more stable codebase by catching potential problems early. As Alice Moore noted [2], the real challenge isn’t just speed – it’s about what each tool leaves behind in your codebase.
Conclusion
Our analysis examined the technical debt introduced by each tool, highlighting that speed alone doesn’t tell the full story. For instance, Claude Code completed tasks in 9 minutes and 9 seconds, compared to OpenCode’s 16 minutes and 20 seconds – a 45% time advantage. However, this quicker finish comes with trade-offs [2][3].
The two tools take very different approaches to validation. Claude Code focuses on specific test subsets, while OpenCode runs the entire test suite to identify system-wide regressions [2]. This difference has practical implications. Claude Code keeps existing comments intact but skips deeper refactoring, which can leave documentation outdated [2]. In contrast, OpenCode ensures consistency by renaming everything, including comments, which helps avoid architectural decay. This attention to detail can significantly impact developer onboarding, potentially cutting it from five weeks to two [7].
For production environments where stability is critical, OpenCode’s comprehensive test suite and thorough refactoring help mitigate long-term technical debt by ensuring the entire system is validated before completion [2].
On the other hand, Claude Code shines in early development phases when speed is the priority. Its faster completion times and features like native checkpoints (Esc×2) make it a strong choice for quickly reaching an "80% solution" [2][3]. However, users should be prepared to manually update documentation and address hidden regressions later [2].
Ultimately, the decision isn’t just about speed – it’s about how much technical debt you’re willing to manage over time. Your choice should align with your project’s current phase, not just its deadlines.
FAQs
How was “tech debt” measured in this test?
When evaluating "tech debt", the focus was on how each AI tool influenced the codebase over time, particularly in terms of maintainability and complexity. The assessment considered several key aspects, such as the level of manual intervention required, the overall quality of the code, and the risk of system bloat.
OpenCode’s declarative approach helped minimize context overhead, making it easier to manage. On the other hand, Claude Code, while offering quick execution, occasionally left behind residual complexity that could complicate future work. To get a full picture, long-term factors like refactoring needs and maintenance costs were closely tracked to understand their broader impact.
Which tool is safer for production changes with regressions at stake?
OpenCode stands out as the safer choice when dealing with production changes that could involve regressions. Its approach prioritizes thorough validation by running a full suite of tests, significantly reducing the chances of introducing technical debt. On the other hand, while Claude Code offers faster results, it relies on subset testing, which can leave room for regression risks. For critical production environments, OpenCode’s focus on safety and comprehensive testing ensures a more dependable and risk-averse solution.
How can teams reduce hidden debt when using the faster tool?
To minimize hidden tech debt when using faster tools like Claude Code, teams should focus on implementing thorough review processes and establishing strong workflows. This means incorporating key practices such as:
- Manual code reviews: Ensure human oversight to identify potential issues that automated tools might miss.
- Comprehensive test suite validation: Run extensive tests to confirm the code functions as expected.
- Runtime testing: Simulate real-world conditions to spot failures early.
It’s essential not to rely too heavily on AI-generated code. While these tools can save time, they might fall short when faced with real-world scenarios. To stay ahead of potential problems, teams should regularly refactor their code, provide clear context for AI tools, and carefully manage interactions with AI to maintain control over the development process. These steps help prevent the gradual accumulation of technical debt.







Leave a Reply