
What the First 90 Days Look Like When You Hire a Rescue Team for Your Failing Codebase
Huzefa Motiwala April 8, 2026
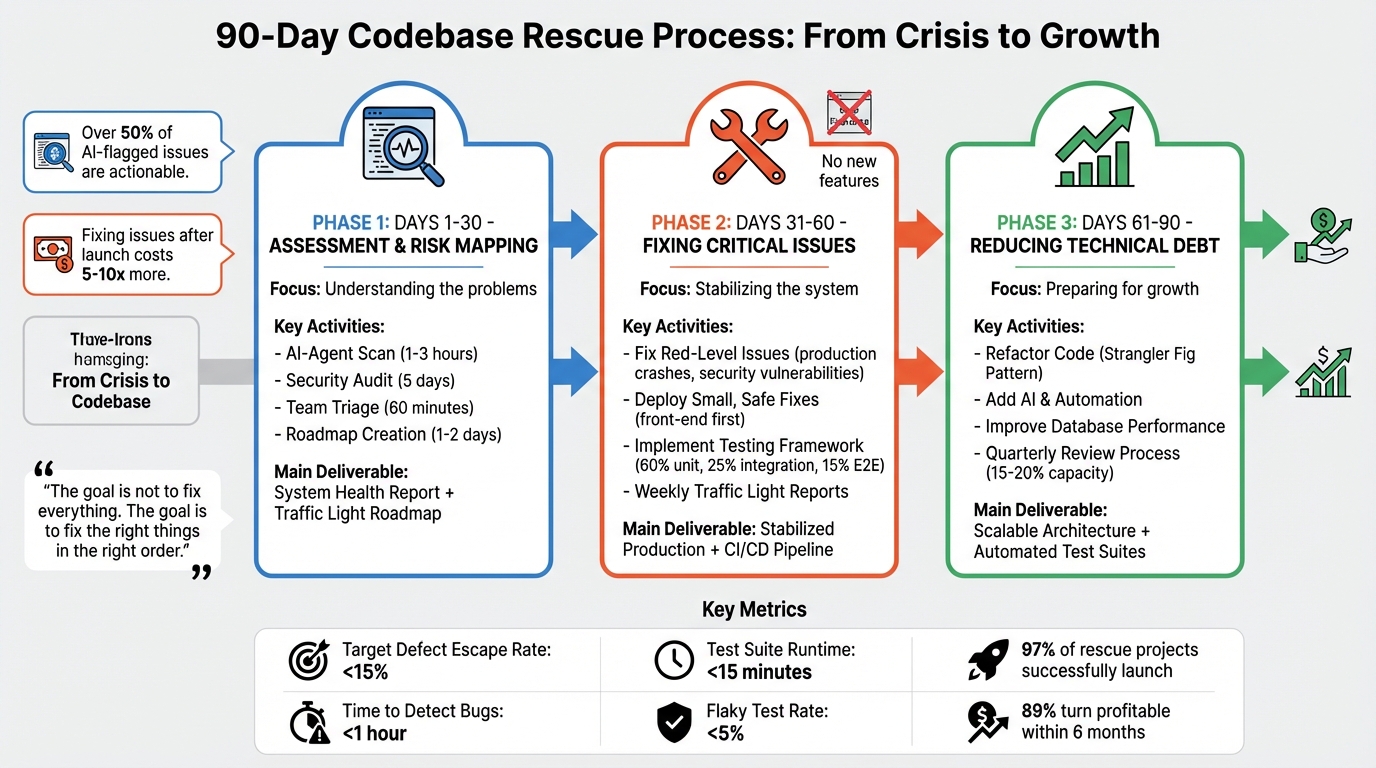
When your codebase is falling apart, the first 90 days with a rescue team are critical. This period focuses on understanding the problems, stabilizing the system, and preparing for future improvements. The process is divided into three phases:
- Days 1–30: The team assesses the codebase, identifies risks, and creates a detailed roadmap to prioritize fixes.
- Days 31–60: They address urgent issues, stabilize production, and implement strict testing and monitoring processes.
- Days 61–90: The focus shifts to reducing technical debt, improving workflows, and setting up scalable systems.
90-Day Codebase Rescue Timeline: Assessment to Stabilization
Manage Technical Debt LIKE THIS, & Thank Me Later
sbb-itb-51b9a02
Phase 1: Days 1-30 – Assessment and Risk Mapping
The first month is all about establishing a clear baseline for the system. During this phase, a rescue team dives deep into the codebase to assess current challenges and forecast potential failures. Using AI-powered tools alongside expert analysis, they map out every risk before making any changes.
Running AI-Agent Assessment on the Codebase
Before jumping into fixes, a thorough technical scan is essential. Tools like Claude Code or Codex CLI perform a full review of the codebase, scanning every file for architectural flaws, security vulnerabilities, performance issues, and technical debt. For a codebase with around 50,000 lines, this process typically takes anywhere from 20 minutes to a few hours [4]. The goal? Maximize speed and coverage – identifying problems that could take weeks to uncover manually.
The AI focuses on specific warning signs: hardcoded API keys, SQL injection risks, N+1 query inefficiencies, "AI architectural amnesia" (where individually sound features clash in unexpected ways), and "package hallucinations" (non-existent libraries suggested by AI, which could open doors for attackers) [3].
"AI doesn’t remember your architecture. Every prompt is a fresh start… you get three features that each make perfect sense in isolation and absolute chaos when combined." – Paul the Dev [3]
Interestingly, a 30-day pilot often verifies that over 50% of issues flagged by AI tools are actionable [4].
Building the System Health Report
The System Health Report serves as the definitive guide to the codebase’s current state. It compiles data on velocity history, bug counts, deployment frequency, and fragile areas – those parts of the system where even small changes can spiral into bigger problems [5]. This report establishes baseline metrics like defect rates and code review cycle times, providing the team with a benchmark to measure progress over the next two months.
One critical focus is identifying tightly coupled components – areas where minor updates, such as a UI tweak, require a complete system redeployment [3]. The report also highlights dead code and unused files, which often add confusion without contributing value. Ultimately, it gives founders a clear picture: Is this codebase salvageable, or is a rebuild the only viable option?
| Phase 1 Activity | Duration | Primary Goal |
|---|---|---|
| AI-Agent Scan | 1-3 Hours | Identify architectural gaps and technical debt [4] |
| Security Audit | 5 Days | Detect OWASP Top 10 vulnerabilities and hardcoded keys [6] |
| Team Triage | 60 Minutes | Align on which AI findings are actionable [4] |
| Roadmap Creation | 1-2 Days | Categorize issues into Red, Yellow, and Green priorities [3] |
Once the system’s condition is thoroughly documented, the team uses this information to organize issues into a Traffic Light Roadmap.
Creating the Traffic Light Roadmap
After completing the System Health Report, the next step is sorting issues into a Traffic Light Roadmap with three categories: Critical (Red), Managed (Yellow), and Scale-Ready (Green). This roadmap prioritizes problems based on severity, ensuring the team tackles the most urgent ones first.
- Red-level issues are immediate threats – things like production crashes, data leaks, hardcoded secrets, and security vulnerabilities. These are the kinds of problems that could cripple the business if left unresolved.
- Yellow-level issues are inefficiencies that slow down development, such as duplicate logic or missing documentation. While not immediately dangerous, they hinder productivity.
- Green-level components are stable and ready for scale. These don’t require immediate attention and can be left as-is.
This structured framework ensures the team focuses on what matters most. Addressing architectural and security issues after launch can cost 5-10 times more than fixing them during this initial phase [3]. That’s why getting the prioritization right at this stage is so critical.
Phase 2: Days 31-60 – Fixing Critical Issues and Stabilizing Production
With the Traffic Light Roadmap in place, the rescue team transitions from diagnosing problems to taking action. The focus during this phase is clear: stabilize the system and tackle critical issues head-on. No new features are introduced; instead, the team zeroes in on making the codebase secure and reliable.
Tackling Red-Level Issues First
Red-level issues are the kind that can bring the entire system down – think production crashes, data corruption, SQL injection vulnerabilities, or hardcoded secrets. To manage these effectively, the team uses a three-factor framework: Severity, Likelihood, and Fixability. Based on this, issues are categorized into four groups:
- Fix Now: High-severity, high-likelihood problems, like service-crashing exceptions.
- Quick Wins: Low-to-moderate severity issues that are easy to address, such as cleaning up dead code or stabilizing flaky tests.
- Schedule for Later: High-effort tasks like database migrations that require long-term planning.
- Accepted Risk: Low-impact issues where the cost of fixing outweighs the benefit.
As VibeRails puts it, “The goal is not to fix everything. The goal is to fix the right things in the right order” [7]. To stay focused, the team freezes the scope of work, deferring any new feature requests to a "parking lot" for future consideration [5].
Once the most critical issues are identified, the team begins deploying fixes in a controlled manner.
Deploying Small, Safe Fixes
The team adopts a cautious approach, rolling out fixes incrementally with a strict Definition of Done that includes thorough testing and detailed documentation. Before writing any new code, they implement end-to-end tests for all customer-facing features. This serves as a safety net for future changes [1][5].
Fixes start with front-end updates (JavaScript, CSS, HTML). These changes are easier to test and less likely to affect sensitive backend systems [1]. To further stabilize the process, the team enforces a formal code review system, ensuring every change is carefully vetted before deployment [5].
Some key practices during this phase include:
- No Friday Deployments: Avoiding weekend incidents by halting deployments at the end of the workweek [1].
- Freezing External Changes: Blocking deployments from previous vendors or external agents to maintain control [2].
- Improved Monitoring and Logging: Setting up basic monitoring tools to catch issues early [5].
The team also builds a robust testing framework, following the "testing pyramid" approach:
- 60% Unit Tests: Focused on individual components.
- 25% Integration Tests: Ensuring different parts of the system work together.
- 15% End-to-End Tests: Validating user workflows.
A four-stage CI/CD pipeline automates safety checks:
- Pre-commit linting and type checking.
- PR-level unit and integration tests, running in under 5 minutes.
- Post-merge end-to-end tests, running in under 15 minutes.
- Post-deploy smoke tests in production, running in under 2 minutes to allow immediate rollbacks if needed.
Security is also a priority. Tools like Semgrep are integrated at the PR level to block high-risk vulnerabilities, such as SQL injection or hardcoded secrets. This approach speeds up vulnerability fixes by up to 9x compared to traditional full scans [9].
With these measures in place, the team tracks progress systematically through weekly updates.
Monitoring Progress with Weekly Updates
The team uses weekly Traffic Light Reports to track progress and keep stakeholders informed. These reports compare current metrics – such as defect rates and deployment frequency – against the baseline established in Phase 1. This transparency helps rebuild trust in the team’s ability to deliver [5].
Key metrics monitored during this phase include:
| Metric | Target (by Day 90) | Why it Matters |
|---|---|---|
| Defect Escape Rate | < 15% | Measures how many bugs reach production versus being caught in testing [8]. |
| Time to Detect | < 1 hour | Ensures bugs are quickly identified after deployment [8]. |
| Test Suite Runtime | < 15 minutes | Prevents developers from skipping tests due to long runtimes [8]. |
| Flaky Test Rate | < 5% | Builds trust in the automated test suite [8]. |
| Deployment Frequency | No decrease | Ensures stabilization efforts don’t slow down shipping [8]. |
One crucial insight: vulnerabilities left open for more than 90 days are rarely fixed – just 9% of such issues are ever resolved [9]. This makes the 90-day mark a critical checkpoint rather than a strict deadline. As Braden Riggs from Semgrep explains, "Treat 90 days as an escalation point, not a deadline but a forcing function" [9]. This mindset ensures critical issues don’t linger and become permanent technical debt.
Phase 3: Days 61-90 – Reducing Technical Debt and Preparing for Growth
With the system stabilized in Phase 2, the focus of Phase 3 shifts toward creating a foundation for long-term success. The next 30 days are all about tackling technical debt in a structured way while ensuring the codebase is ready to scale efficiently.
Refactoring Code Without a Full Rewrite
Now that the critical issues are addressed, it’s time to chip away at technical debt. Instead of rewriting everything from scratch, the team uses strategies like the Strangler Fig Pattern and feature flags to modernize the code incrementally. Rollouts start small – around 5% – and expand to full deployment as confidence grows [11].
Before diving into legacy code, the team writes characterization tests to capture the existing behavior of the system. These tests act as a safety net, helping to avoid regressions during refactoring [11][12]. Pull requests are intentionally kept small – usually under 200 lines – and focus on one task at a time, such as renaming variables, reorganizing modules, or adding type annotations. This methodical approach ensures changes are manageable and easy to reverse if needed.
Database updates follow the Expand-Contract Refactoring method, which involves adding new schema elements, synchronizing data, and then removing outdated structures [11].
To prioritize tasks, the team uses a Risk-to-Effort scoring system. This involves dividing the Risk Score (impact of not fixing an issue) by the Complexity Score (effort required). High-risk, low-effort tasks, like removing hardcoded secrets or fixing N+1 database queries, are tackled first. A Technical Debt Register keeps track of all identified issues, including their type, location, and scores. This register generates a "top 20" list of priorities, ensuring the team focuses on the most impactful improvements [10].
Adding AI and Automation to Workflows
AI and automation tools come into play to streamline maintenance and enhance developer productivity. The team uses AI-assisted refactoring for specific tasks, such as migrating legacy AngularJS components to React, generating unit test suites, and automating syntax upgrades [13]. For example, in early 2026, a financial services company achieved an 80% automation rate, cutting their upgrade time almost in half [13].
Developers remain in control of AI-generated outputs. The "30-Second Rule" is enforced: if a developer cannot clearly explain AI-generated code within 30 seconds, it doesn’t go into production [3]. This approach prevents "architectural amnesia" and ensures the code remains maintainable. Security scans using tools like Semgrep and SonarQube are also part of the workflow, catching vulnerabilities and package errors before deployment [3].
Testing and deployment processes are automated with tools like Playwright and ESLint. Centralized secret management solutions, such as Infisical or 1Password CLI, are implemented to further reduce manual intervention [3]. These automation practices help create a resilient and scalable system.
Setting Up the System for Long-Term Stability
Beyond automation, the team focuses on building a scalable architecture and establishing strong governance practices. They enforce modular architecture principles by separating business logic into dedicated services and managing data persistence through repositories. This approach aligns with the Single Responsibility Principle, making the codebase easier to extend and less prone to bugs [3].
Infrastructure is managed through Infrastructure as Code (IaC), removing the need for manual configurations [2]. Detailed runbooks and incident response procedures are created to ensure smooth operations and streamlined handovers [2]. The emphasis remains on minimizing risk while maintaining a high level of reliability.
Database performance is improved by addressing N+1 query issues through eager loading and proper indexing [3]. For instance, in January 2024, Kong, an API management company, adopted a micro-frontend architecture. This change reduced their pull request-to-production time from 90 minutes to just 13 minutes and nearly doubled their weekly deployment frequency [3].
To keep technical debt under control, quarterly reviews are introduced. Engineering teams dedicate 15–20% of their capacity to debt reduction on an ongoing basis, avoiding the need to halt feature development entirely [10].
"Technical debt is the mortgage on your codebase. Every shortcut you take… are the interest payments that slow down every future feature and compound over time." – Mark Rachapoom [10]
What Gets Delivered Across the 90 Days
A rescue engagement focuses on delivering targeted results that address immediate problems, stabilize operations, and prepare the system for future growth.
Deliverables by Phase
Phase 1 (Days 1–30) is all about understanding the current state of the system. During this stage, the team compiles a System Health Report after a detailed 5-day review. This includes an OWASP Top 10 security audit and a look at infrastructure costs [6]. A Traffic Light Roadmap is delivered to prioritize issues by urgency. Additionally, a Context Packet is provided, summarizing affected services, recent changes, anomalies, and incident histories [15]. The team also creates a Service Map, which includes stable identifiers for every service, complete with consistent environment tagging and ownership details [15].
Phase 2 (Days 31–60) focuses on immediate fixes and stabilization. This includes addressing security vulnerabilities, stabilizing deployment pipelines, and resolving critical bugs that cause production issues [6]. The team defines action tiers, ranging from read-only assessments to reversible interventions like feature flag rollbacks or service restarts [15]. Auditability logs are provided, capturing evidence, proposed actions, approvals, and execution timestamps [15]. To keep everyone in the loop, internal communication drafts are shared, outlining what’s been discovered, what’s being tested, and when updates will be provided [15].
Phase 3 (Days 61–90) shifts to long-term improvements. Deliverables include refactored modules, automated test suites using tools like Playwright, and automated runbooks with clear execution paths [15]. A pilot program for automated, reversible workflows is launched to handle frequent minor incidents [15]. The team also delivers a strategic growth plan aligned with the company’s business objectives [14].
To ensure everything stays on track, the rescue team employs specialized tracking and risk management tools throughout the process.
Tools Used for Tracking and Risk Management
Managing these deliverables requires a range of tools designed for transparency and control. AI-Agent Assessment and static analysis tools like SonarQube, CodeClimate, and Semgrep help identify security and code quality issues before they reach production [3]. Secret management tools, such as Infisical or the 1Password CLI, prevent hardcoded credentials [3]. Testing frameworks like Playwright validate systems end-to-end, while pre-commit hooks scan for exposed API keys and other sensitive data [3].
The Traffic Light Roadmap remains the primary tool for tracking progress throughout the engagement. Decision logs and READMEs document architectural choices, reducing the risk of inconsistent patterns, often referred to as "AI architectural amnesia" [3]. Cloud billing alerts are set at 50%, 80%, and 100% of the budget to catch runaway processes or unauthorized compute usage [3].
"The goal is to improve incident response in measurable ways: faster time to context, cleaner ownership routing, safer mitigations, and stronger learning capture without weakening control." – Andre King, Rootly [15]
These tools and processes turn the engagement into actionable improvements that benefit both company leadership and teams.
Results for Founders and Teams
By the end of the 90 days, founders see clear operational improvements. Teams can start incident response with a pre-generated context packet instead of wasting time on manual searches. Misroutes decrease, and incident records require less manual reconstruction [15]. The system becomes stable enough to scale, and technical debt no longer eats up 60–80% of the maintenance budget [3]. Security vulnerabilities are addressed, making the codebase ready for investor scrutiny [6].
Teams also benefit from faster deployment cycles and reduced onboarding times. For instance, in January 2024, Kong implemented a micro-frontend architecture that cut PR-to-production time from 90 minutes to just 13 minutes, nearly doubling their weekly deployment frequency [3].
"The point of the first 90 days is not maximum automation. It is repeatable control and measurable operational improvement." – Rootly [15]
Conclusion
The first 90 days of rescuing a codebase follow a structured process: assess the damage, stabilize production, and set the stage for growth. These steps move from pinpointing critical issues to securing operations and finally tackling technical debt to support future scalability. Along the way, tangible outcomes emerge, such as detailed System Health Reports, actionable Traffic Light Roadmaps, refactored code modules, and automated test suites. This approach doesn’t just stabilize your systems – it creates a foundation for sustainable growth.
AlterSquare takes a highly focused approach to rescue efforts, prioritizing operational continuity while addressing deeper issues. This method minimizes risk and strengthens the system for long-term reliability. By the end of 90 days, 97% of projects under rescue successfully launch, and 89% turn profitable within six months [16]. Teams also benefit from quicker deployments and smoother onboarding processes, demonstrating how small, targeted improvements can lead to big results.
Achieving stability doesn’t mean rewriting everything from scratch. Instead, it’s about making incremental changes that address immediate concerns while building resilience for the future. To ensure every decision aligns with both technical needs and business goals, AlterSquare’s Principal Council personally audits each system before work begins.
FAQs
How do I know if my codebase should be rescued or rebuilt?
Deciding whether to rescue or rebuild your codebase comes down to its current state.
If the core data models are solid, the code still aligns with its original goals, and incremental fixes can bring stability, then a rescue approach might work. On the other hand, if the codebase is overwhelmed by technical debt, has suffered from scope creep, or faces severe integration challenges, rebuilding might be the smarter move.
The key is conducting a thorough evaluation of the architecture and technical debt. This analysis will provide the clarity needed to make the right call.
Will stabilization work stop us from shipping new features?
Stabilization efforts aim to tackle urgent risks and technical debt while keeping development moving forward. Techniques like phased updates, feature flags, and careful risk management help modernize systems step by step, ensuring progress without pausing feature rollouts. Although the pace of releasing new features might shift, the goal is to build a stronger, more dependable foundation that supports both current enhancements and long-term growth.
What access and documentation does a rescue team need from us?
To thoroughly evaluate and stabilize your codebase, a rescue team requires a few key things:
- Complete access to the codebase, including all repositories, to perform audits and pinpoint issues effectively.
- Context on the system and architecture details to grasp dependencies and the overall structure.
- Historical records, such as past audits or technical debt reports, to help prioritize what needs fixing.
Supplying this information enables precise diagnostics, prioritization of risks, and seamless implementation, all while avoiding disruptions to live operations.





Leave a Reply