

Micro-frontends help only when teams need separate release cycles on the same product. If not, they often turn into extra build work, version drift, and team-to-team blockers within 12–18 months.
Here’s the short version:
- Keep state local. Shared stores often turn into hidden contracts that slow every team down.
- Use clear app-to-app contracts. Typed events, versioned payloads, and URLs are safer than direct state sharing.
- Pin core dependencies. If React, design system packages, or shell contracts drift, errors often show up at runtime instead of build time.
- Set CI/CD rules early. A 2024 study cited in the article found "No CI/CD" scored 10/10 for harm, and 90% of people had seen it in live projects.
- Split by business domain, not UI parts. A domain team can ship and fix its own slice. A shared "header team" often becomes a bottleneck.
- Keep the shell thin. Let it handle top-level routing, error isolation, and telemetry – not shared business state.
If I had to sum up the article in one line, it would be this: micro-frontends do not remove coordination; they only move it. The setups that hold up after 18 months are the ones that keep boundaries clear, contracts explicit, and releases independent.
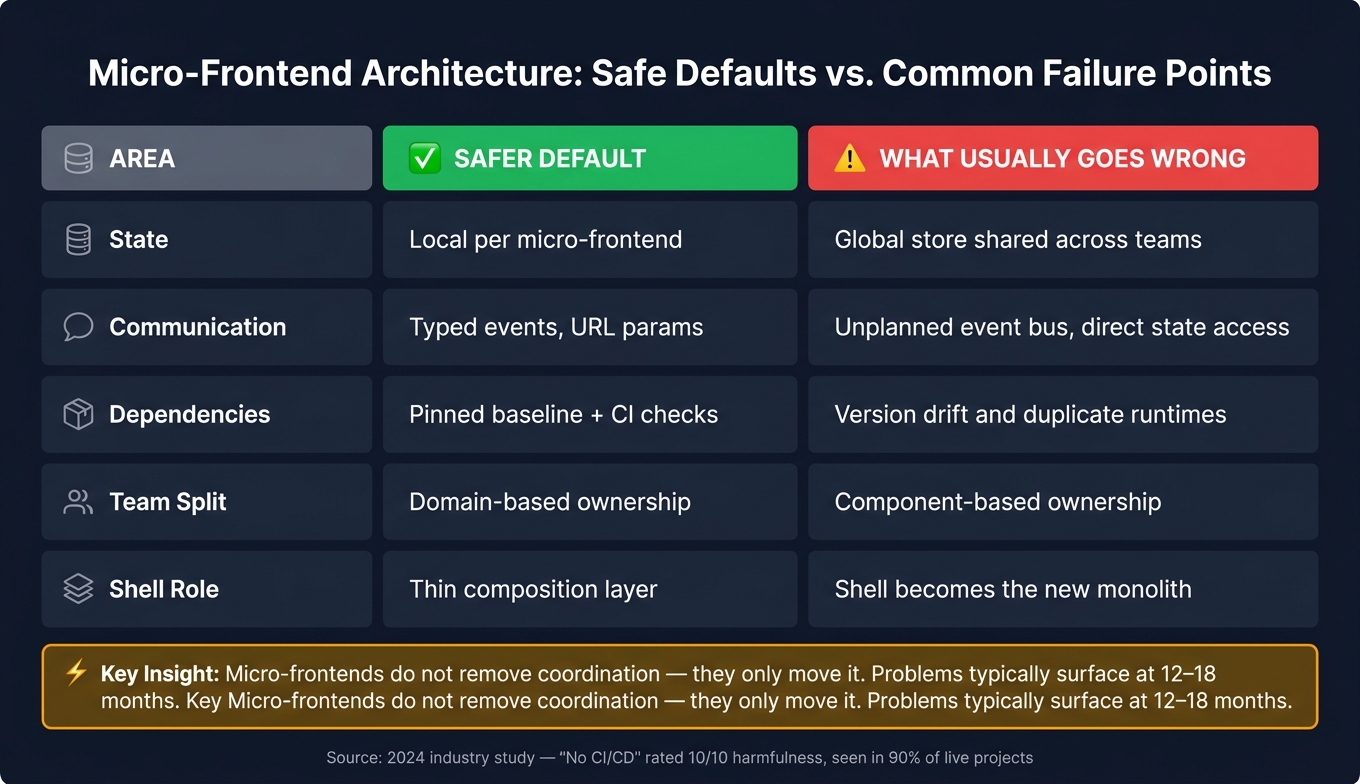
A quick view of the core choices:
| Area | Safer default | What usually goes wrong |
|---|---|---|
| State | Local per micro-frontend | Global store shared across teams |
| Communication | Typed events, URL params | Unplanned event bus, direct state access |
| Dependencies | Pinned baseline + CI checks | Version drift and duplicate runtimes |
| Team split | Domain-based ownership | Component-based ownership |
| Shell role | Thin composition layer | Shell becomes the new monolith |
So if you’re deciding whether to use micro-frontends, I’d ask one question first: Do your teams need independent delivery badly enough to pay for the extra coordination work?
Micro-Frontend Architecture: Safe Defaults vs. Common Failure Points
Frontend Nation 2024: Luca Mezzalira – Micro-Frontends Anti-Patterns
Shared State and Communication: The Coupling Problem You Miss Early On
Shared state is usually where micro-frontends start to lose their freedom. It often begins with a small shortcut: a global store in the shell, or a few window events passed between apps. At first, that can seem harmless. Then teams try to ship on their own schedules, and those hidden links start causing trouble. The first big failure mode is shared state and communication.
As Cam Jackson notes, sharing domain models creates coupling that becomes hard to unwind. [1]
How Shared State Gets Out of Control
The most common trap is a shared global store – Redux, Zustand, or something similar – living in the shell and used across remotes. The store shape turns into a hard contract that every team has to follow. The second one team needs to change its data model, it has to check with every other team touching that store. Independence turns into meetings.
Ad hoc event buses are the next problem. Teams wire up window events with no schema, and suddenly the flow of data is hard to follow in production. Debugging turns into archaeology. You end up digging through old handlers, guessing which app fired what, and hoping the payload still looks the way you think it does.
Shared framework context breaks down for a similar reason. If teams run different framework versions, shared context can fail at runtime. Worse, those failures may not show up during isolated testing.
Over time, these patterns lead to hidden regressions and blocked releases. Remotes stop being deployable on their own, and the promised team freedom gets buried under coordination work. [8][7]
State Patterns That Hold Up Over Time
The default rule should be simple: keep state local. Local state protects the release independence micro-frontends are supposed to give you. Each micro-frontend should own its own data and fetch what it needs on its own. In most cases, duplicate fetches cost less than the team overhead that comes with shared state.
When apps do need to communicate, typed CustomEvents with versioned schemas are a safer choice than direct store access. The URL is also easy to overlook here, but it works well. Query parameters and hash fragments survive reloads, can be bookmarked, need zero runtime coupling, and are easy to inspect in any browser.
For cross-cutting concerns, use clear contracts and clear ownership instead of a shared in-memory object. Consumer-driven contract testing can help check that shell and remote interfaces stay stable without forcing teams to deploy at the same time.
| Communication Method | Coupling Level | Long-Term Risk |
|---|---|---|
| Shared Redux/Zustand Store | High | One change breaks all teams |
| Shared Framework Context | High | Version mismatches break runtime context |
| Ad hoc Event Bus (no schema) | Medium | Data flow becomes untraceable |
| URL / Query Params | Low | Resilient and easy to debug |
| Custom Events (typed, versioned) | Low | Explicit contracts with clear ownership |
What to Decide Before You Build
Before writing any code, set one simple rule: state stays local unless it is plainly cross-cutting. If two micro-frontends need the same data, the default answer should be two API calls, not one shared store. If shared communication is needed, define the event payload schema up front, version it, and document who owns it.
Treat any data flow across micro-frontends as an architecture risk signal. If one team starts reaching into another team’s remote to read state, that’s a boundary violation and should be flagged right away.
Every communication path needs to be explicit, versioned, and owned.
Once state is local and explicit, dependency versioning becomes the next constraint.
Versioning and Dependencies: How Independent Frontends Slowly Tangle
Version drift usually starts out harmless. Each team upgrades on its own timeline, and for a while, everything seems fine. Then, somewhere around 12 to 18 months later, those gaps start to bite. One team is on React 18.3, the shell is still on 18.2, and another team is stuck on an older release because a third-party package refuses to budge.
That’s when the setup starts sliding back toward the very monolith you were trying to escape. The strain shows up first in shared libraries. Teams may look independent on paper, but that independence shrinks fast when they no longer run the same versions.
Why Dependency Drift Gets Costly
Shared libraries turn into release blockers as soon as more than one team depends on them. The nasty part is where these issues show up: often at runtime, when they’re much harder to track down.
In a monolith, version conflicts usually break at build time. In a micro-frontend setup, they can surface later as cryptic "Invalid hook call" errors in production that don’t show up locally [4][10]. That’s a rough place to debug anything.
Design system drift is slower, but users can see it. Different component versions can quietly create mismatched button styles, spacing, and typography across the same page [3][4]. Nothing crashes, but the product starts to feel patched together.
The next piece is understanding what runtime loading fixes – and what it doesn’t.
What Module Federation Solves and What It Does Not
Runtime negotiation helps, but only if version ranges overlap. Module Federation lets the host and remote settle on which shared library version to load. Setting singleton: true stops React from loading twice, which matters for hooks and context propagation.
But there’s a catch. If those version ranges don’t overlap, you can still end up with duplicated runtimes or runtime errors. And if strictVersion: true isn’t set, that mismatch may fail in ways that are easy to miss at first [4][10].
| Feature | Build-Time Integration (npm) | Run-Time Integration (Module Federation) |
|---|---|---|
| Coupling | High: the shell must be rebuilt for remote changes | Low: remotes can deploy independently |
| Deployability | Lockstep release required | Independent deployments |
| Version Control | Standard npm versioning and lockfiles | Runtime negotiation via remoteEntry.js |
| Debugging | Easier: standard tooling and source maps | Harder: debugging spans separate bundles |
| Bundle Size | Better tree-shaking and deduplication | Risk of duplicated runtimes and extra overhead |
Dependency Governance That Scales With Your Team
The most practical fix is a pinned dependency baseline. That can be a shared internal package or a package.json template that sets the exact versions of core libraries for every remote. For shared singletons, pinned versions work better than flexible ranges [3].
It also helps to pair that baseline with a CI compatibility gate. Before deploy, check a remote’s shared dependency versions against the shell’s baseline. If they don’t match, fail the build early [3][9].
That approach stops version skew before it piles up and turns a core library upgrade into a messy, multi-team scheduling problem.
Version discipline helps, but it doesn’t make the build and deployment side any simpler.
sbb-itb-51b9a02
Build, Deployment, and Team Boundaries: Where Complexity Piles Up
Once dependency versions are pinned, the next place things go wrong is build and release. That’s where micro-frontends often move complexity out of the codebase and into CI/CD, runtime environments, release timing, and team agreements.
Independent pipelines sound great on paper. They keep working until standards drift, environments stop matching, and release coordination turns fragile. A 2024 study of industry practitioners ranked "No CI/CD" as the most harmful micro-frontend anti-pattern, with a median harmfulness score of 10 out of 10. On top of that, 90% of respondents had seen it in live projects [5]. That’s a pretty blunt signal. Use shared pipeline templates, make builds portable across environments, and keep ownership with the teams doing the work.
The quieter problem is the distributed monolith. Teams may own separate repos, yet still have to release together because the product slices aren’t independent in practice. In that setup, autonomy exists in code, but not in delivery.
Why Poor Team Boundaries Create Coordination Debt
Component-based boundaries tend to pull teams into each other’s work. Domain-based boundaries cut that down.
A "header team" or a "button library team" can sound neat at first. Then every feature that touches shared navigation turns into a round of Slack messages, reviews, and scheduling. It’s death by a thousand handoffs. Domain-aligned ownership changes that. When one team owns a business slice end to end, it can ship, debug, and iterate without waiting for another team to bless the change.
Here’s the difference:
| Boundary Type | Coordination Cost | Deployability | Accountability |
|---|---|---|---|
| Component-based | High; constant negotiation over shared UI elements | Low; changes often break multiple pages | Diffuse; "everyone owns it, so no one does" |
| Domain-based | Low; teams communicate via stable contracts and events | High; independent release cycles per feature | Clear; one team owns the outcome from DB to UI |
Guardrails to Put in Place in Year 1
Once boundaries are set, the next step is making sure the shell and remotes behave in a steady way when something fails. Year 1 is the time to lock in the defaults that let teams stay independent later.
A thin shell, or composition layer, should own top-level routing and not much else. Each micro-frontend should own its own route subtree. Every remote should sit behind an error boundary, so one broken domain doesn’t bring down the whole application shell. Telemetry and errors should include mfe_name and mfe_version, which makes it much easier to trace an issue back to the right team and deployment [2][6].
On the governance side, keep a small architecture council in charge of shared standards like the design system, dependencies, and integration contracts. The point isn’t to add red tape. It’s to keep these calls consistent and low-drama, so teams aren’t arguing over the same things every quarter.
Conclusion: A First-Year Playbook for Decisions That Hold Up at 18 Months
Four choices tend to separate steady micro-frontends from setups that get painful to change later: local state, dependency control, release discipline, and domain ownership. Each one shapes where coupling shows up down the road. The main risk isn’t just technical complexity. It’s coupling that arrives late, after the system already feels set.
That’s what makes these decisions tricky. In month 3, a shortcut can feel harmless. By month 18, that same shortcut can turn into coordination debt across teams. So micro-frontends should solve an organizational problem, not just reflect a style preference.
For small teams, a monorepo will often handle most MVP needs with less overhead. Micro-frontends are a scaling tool for organizations. They start to make sense when several autonomous teams are getting blocked by one shared release cycle.
If the seams are clear in year 1, they’re much easier to manage at month 18.
FAQs
When are micro-frontends worth the overhead?
Micro-frontends are mostly an organizational move, not just a code or architecture decision. They tend to be worth the extra overhead when four or more autonomous teams work on the same product surface and keep getting slowed down by a single release train.
That said, they only make sense when you have dedicated DevOps support and stable, clear domain boundaries. Without those two pieces, things can get messy fast.
If you have fewer than three teams, or your main goal is performance or legacy modernization, a modular monolith is usually the more efficient and cost-effective option.
How much shared state is too much?
It becomes too much when features rely on it so tightly that teams end up building messy, failure-prone dependencies. At that point, you don’t have clean separation anymore – you’ve basically rebuilt a distributed monolith.
Micro-frontends work best when each part has a clear bounded context and shares very little state or business logic with other parts. If teams do need to share data or coordinate behavior, loose coupling is usually the safer path. That means using custom events or reactive streams instead of tying everything to one shared store.
If domain boundaries keep shifting, or if features depend heavily on each other, a modular monolith is often the better choice.
What should the shell own?
The shell should act as a lightweight orchestrator that stitches micro-frontends together at runtime, not as a home for business logic.
It should handle the top-level layout, routing, authentication guards, and the shared design system provider. Keep it minimal and framework-agnostic, and leave domain-specific work to remote modules owned by each team.







Leave a Reply