
When AI Agents Open Dozens of PRs: The Code-Review Burden Teams Underestimate
Taher Pardawala June 22, 2026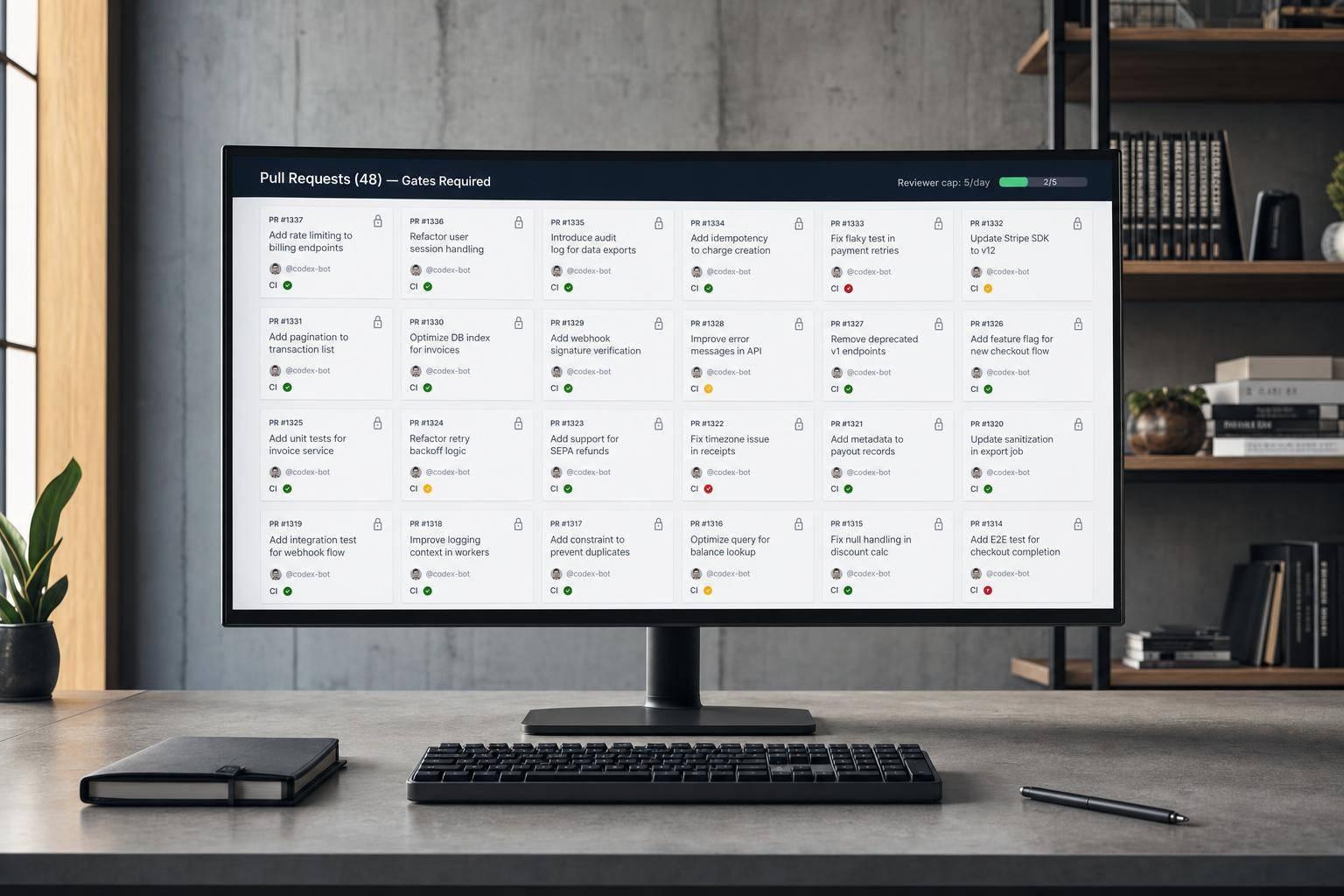
AI can write more code than your team can review. That is the main problem.
If I had to boil this article down to a few lines, I’d say this:
- PR volume can jump far faster than review capacity
- More AI-written PRs do not mean more shipped work
- Review time, stale PRs, and hidden bugs can pile up fast
- The fix starts with ownership, CI gates, PR limits, and review caps
A few numbers make the point fast:
- Median PR review duration went up 441.5% in high-AI teams
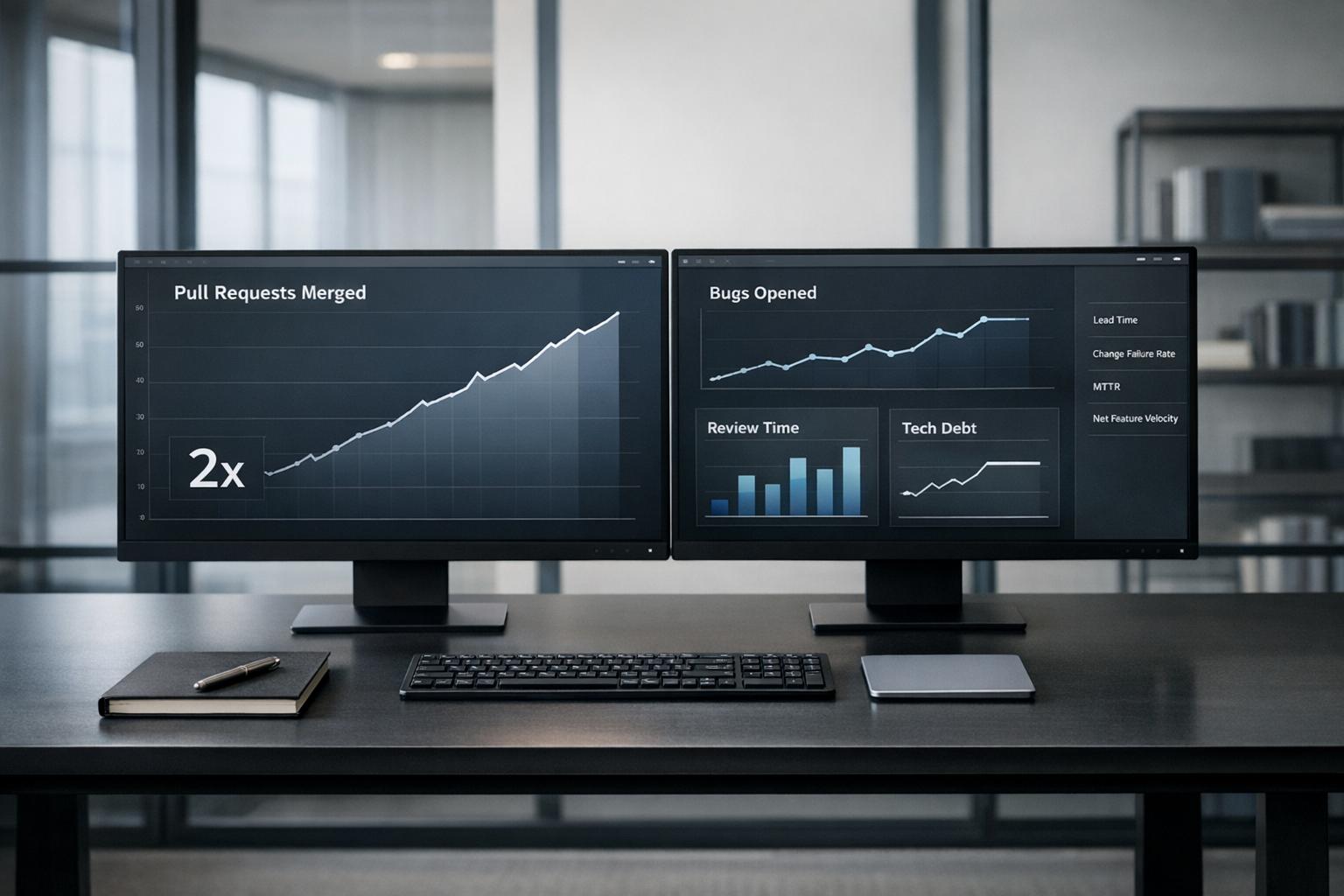
- Pull requests per developer rose 98%
- Feature-branch throughput grew 59% year over year
- Merged code still fell by 7%
- Zero-human-review merges rose by 31%
- Reported defect rates grew from 9% to 54% year over year
What do I take from that? More code activity is not the same as more safe delivery.
If you run a team, here’s the short version:
- Treat AI output as a review-capacity problem
- Keep humans in the final approval step
- Route PRs with
CODEOWNERS - Block weak PRs in CI before review starts
- Keep PRs small
- Cap open agent PRs based on how many reviews your team can do in a day
- Give reviewers short intent notes so they are not guessing from the diff alone
Here’s the shift the article is making: the bottleneck has moved from writing code to reviewing code well. And if you do not change the review system, agent-written PRs can turn into a queue your team cannot clear.

AI Code Review Crisis: Key Stats Every Engineering Team Needs to Know
The Problem: How High-Volume AI PRs Break the Review Process
Review Fatigue, Context Switching, and Slower Merge Flow
High-volume agent PRs make review harder because each diff asks someone to rebuild context from scratch. That constant switching slows merge flow.
The numbers show how fast this pileup can happen. AI adoption has been linked to a 98% increase in pull requests per developer, while median PR review time climbed 441%. At the same time, 31% more PRs started merging with zero human review [4].
When the queue doubles or triples, people stop reviewing with the same level of care. They start skimming. They start rubber-stamping. The goal shifts from understanding the change to simply keeping work moving. That’s usually the point where speed starts to eat into quality.
Hidden Defects and Weaker Accountability
Once review gets overloaded, subtle problems slip through. That can mean broken assumptions, tests rewritten to fit bad behavior, or regressions hiding in older code paths. CI can check for consistency, but it does not tell you whether a change actually meets the requirement [3].
That gap matters more now because reported defect rates have gone from 9% to 54% year over year after broad AI adoption [2].
There’s also a people problem here. When intent is hard to piece back together, ownership gets fuzzier. Reviewers are left to guess what the change was supposed to do by reading the diff alone, because the agent’s reasoning is no longer in view. As Addy Osmani put it, the hard part of engineering
"moved from writing code to deciding whether to trust it." [2]
And that trust decision still belongs to humans. The reviewer approves the merge, which means accountability stays with the team even if the agent produced the change [7].
Human-Only PR Flow vs. AI-Heavy PR Flow
This is more than a volume issue. It changes the shape of review itself.
With human-only PRs, reviewers usually share enough background to understand the intent behind the code. With AI-heavy PRs, changes can arrive faster than that shared context can be checked. Review stops being about understanding why and starts leaning more on whether the change seems safe enough to trust.
sbb-itb-51b9a02
Why Teams Underestimate the Review Burden
Metrics That Reward Output Instead of Safe Throughput
This bottleneck is easy to miss because many teams still measure output, not review capacity. Their dashboards cheer for PR count and lines changed. But those numbers show activity, not safe throughput.
Feature branch throughput grew 59% year over year in 2026, yet mainline merges – the work that actually ships to production – fell by 7% [5]. That creates a false sense of momentum. Teams see more motion and assume things are going well, even while review capacity is getting squeezed. A better read comes from metrics like lead time and change-failure rate.
Pre-Agent Review Assumptions That No Longer Hold
Classic PR review was built around a simple setup: one author, one focused change, and a clear path for back-and-forth. AI changes that. Agents can open dozens of PRs at the same time, break one larger change into disconnected micro-PRs, and leave reviewers staring at code without the original context [6][2].
Reviewer capacity is not keeping pace. And when agents get feedback they can’t interpret or fix, they may just abandon the PR. That happens in 3.8% to 10% of agent-authored PRs [1]. So the queue fills with stale changes, and reviewers burn time on work that never lands or gets closed cleanly.
Once that old review model stops working, stale PRs and muddy intent start stacking up fast.
Fragile Codebases Make AI PR Volume More Dangerous
Fragile codebases make heavy AI PR volume more risky because agents often miss unwritten rules. They can’t see the rules buried in Slack threads or sitting in a senior engineer’s head, so they may head in the wrong direction while still producing code that looks polished [5].
One documented case makes the point well. An agent added three API endpoints that passed tests and looked fine, but it imported a v1 MongoDB middleware instead of the v2 MySQL middleware the team had already moved to. The mistake was caught only because a tech lead remembered the rule [5].
Shared-state IaC adds another layer of risk. Concurrent agent work can create race conditions with a high blast radius [8]. In codebases like this, more AI output doesn’t lighten the review load. It adds to it.
That’s why ownership, CI gates, and batching matter.
Why Reviewing AI Code Is So Hard
The Playbook: Making AI PR Volume Manageable for Reviewers
The fix is to treat AI PR volume as a review-capacity problem, not an output problem. That shift matters. If agents can open PRs all day but humans can’t review them at the same pace, the queue backs up fast.
This is how teams keep agent output from burying reviewers.
Set Ownership Boundaries Before Agents Scale Up
Before agents start opening PRs across the codebase, each module should have a clear owner.
CODEOWNERS files are the practical place to start. Map every module to a named owner or team, then connect that routing to approval rules. The level of approval should match the level of risk.
| Risk Tier | Ownership / Reviewer Rule | Merge Policy |
|---|---|---|
| Low-risk (Docs, Lint) | Automated or single peer skim | Auto-merge allowed if CI is green |
| Feature | Standard CODEOWNERS routing |
Human approval required |
| High-risk | Explicit named senior reviewer | No auto-merge; mandatory human sign-off |
| Security / Infra | Domain owner + Security team | Hard block on any CVSS 9.0+ findings [10][11] |
Routing alone isn’t enough. Teams also need restricted modules – places like /auth/ or /billing/ where agents cannot merge without senior human sign-off [11].
And the last merge decision should stay with a person. In a study of 29,585 PR lifecycles, Collaborator tools were ≥96% agent-initiated, but final merge approval remained almost exclusively human [7].
The engineer who triggered the agent should also handle the first-pass review and add intent notes. That gives the next reviewer a head start and cuts down on back-and-forth.
"Reviewing your own pull request isn’t optional when agents are involved. It’s basic respect for your reviewer’s time." – Andrea Griffiths, Senior Developer Advocate, GitHub [9]
Once ownership is clear, teams can take the routine checks off the reviewer’s plate.
Move Mechanical Checks Into CI Before Human Review Begins
Linting, type checks, static analysis, dependency scans, secret detection, and license checks should all run in CI before a human even looks at the PR. If one of those checks fails, the PR stops there.
That same gate should block PRs that remove tests, skip lint steps, or lower coverage thresholds [9].
PR size limits help too, and CI is a good place to enforce them. Defect detection drops from 87% for PRs under 100 lines to 28% for PRs over 1,000 lines [12]. If CI fails oversized PRs, teams keep changes reviewable on purpose instead of hoping reviewers can sort through giant diffs later.
Once the obvious failures are filtered out, reviewers can spend their time on judgment calls instead of housekeeping.
Batch Related Changes and Match Review Depth to Risk
After CI gates, the next bottleneck is context switching. Reviewers lose time when they jump between too many small PRs that have no shared thread.
A better setup is to release agent PRs in daily waves that match review capacity [12]. It also helps to cap open agent PRs at about 2x daily human review capacity so the queue doesn’t harden into a mess [12].
Each PR should include a reasoning trace in the description: the goal, the alternatives considered, and the verification steps taken [3][6]. That gives reviewers the "why", not just the diff.
| Feature | Uncontrolled Micro-PR Flow | Batched / Tiered AI Changes |
|---|---|---|
| Reviewer Time | High (fragmented context switches) | Optimized (focused on logic) |
| Context Retention | Poor (too many small threads) | High (coherent units of work) |
Not every change needs the same depth of review. Business logic, auth flows, and anything tied to data deletion need deeper sign-off from named reviewers.
Agent rollout should be built as a review workflow first and a code-generation tool second.
Conclusion: Review Capacity Is a System Constraint, Not an Afterthought
AI agents don’t help much if review capacity stays flat. They can pour change after change into a repo, but the choke point is still the number of human eyes available to check what gets merged. That’s the limit the earlier sections brought into view.
This isn’t about speed. It’s about a review system that’s now too small for the queue sitting in front of it.
When teams roll out agents without changing how review works, backlog follows. It’s that simple.
The floor is simple too: the operating model comes down to a small set of controls – clear ownership, hard CI gates, PR size limits, work-in-progress caps, and named reviewers for critical paths.
For founders and engineering leads, the signal worth watching is straightforward: if review minutes drop while PR counts climb, quality risk climbs fast too. Treat review throughput like a hard capacity limit before scaling agent output. If the queue can’t absorb the output, slow agent volume first.
FAQs
How many AI PRs should a team allow at once?
There’s no one-size-fits-all number here. The right limit for AI-generated pull requests depends on how much review work your team can absorb without clogging the pipeline.
A good rule of thumb is to cap AI-generated PR volume based on review capacity and throughput, with reviewer use staying below 85%. Once reviewers get pushed past that point, the queue can pile up fast and become hard to manage.
A tiered setup tends to work well:
- Let automated CI handle trivial changes
- Keep a small queue for feature work that needs human judgment
- Apply strict review to critical-path areas
Size matters too. Keep PRs small, and flag changes above 400 to 600 lines for decomposition. Big PRs slow review, hide mistakes, and make it harder for people to give careful feedback.
Which PRs still need deep human review?
Deep human review still matters for PRs that call for architectural judgment, product direction, or team context that AI just doesn’t have.
Put extra attention on PRs that involve:
- Architecture and design
- A broad scope or large blast radius
- Unclear intent or cases where basic clarifying questions weren’t asked
- Quality traps, such as tautological tests, hallucinated APIs, or code that breaks internal patterns
What should teams automate in CI before review?
Before human review, automate the basics so people aren’t wasting time on noise. That means running formatting, style checks, import ordering, and test coverage thresholds up front.
Then layer in triage for risk and authorship. Flag sensitive areas that must get human review, keep PRs within 400–600 lines, and require PR descriptions that spell out intent, verification, and a reasoning trace.
Related Blog Posts
- Your Team Ships 2x More Pull Requests Since Adopting AI. Your Bug Count Also Doubled.
- AI Made Our Best Developers 3x Faster. It Made Everyone Else a Liability
- The AI Productivity Paradox: Your Team Ships More Code but Moves Slower. Here’s Why
- AI Agents Can Now Scan 100K Lines of Code in Hours. Here’s What They Still Miss.






Leave a Reply