

AI adoption in domain-heavy software – like healthcare, finance, and legal tech – faces unique challenges. These systems demand precise workflows, regulatory compliance, and deep industry knowledge, making general-purpose AI models inadequate. Here’s a quick summary of the main issues and solutions:
Key Challenges:
- Data Scarcity: Many industries lack digitized, high-quality, proprietary datasets.
- Complex Workflows: Legacy systems and custom processes are difficult to integrate with AI.
- Fragmented Data: Isolated systems create blind spots, reducing AI effectiveness.
- Bias in AI Models: General AI often embeds biases, leading to inaccurate or unfair results.
Solutions:
- Train AI with Industry-Specific Data: Use structured tasks and synthetic data to improve accuracy.
- Leverage Retrieval-Augmented Generation (RAG): Retrieve real-time, verified facts to minimize errors.
- Develop Custom Models: Tailor AI to specific industries for better precision.
- Human Oversight: Ensure experts review AI outputs in high-stakes environments.
AI in domain-heavy industries requires a tailored approach, combining specialized data, workflow alignment, and human-in-the-loop systems. While challenging, startups using methods like AlterSquare‘s I.D.E.A.L. framework are achieving measurable results in healthcare, finance, and legal tech.
Main Challenges of Adding AI to Domain-Heavy Software
Lack of Industry-Specific Data
One of the biggest hurdles in integrating AI into specialized software is the lack of industry-specific data. A striking 42% of business leaders admit they don’t have enough proprietary data to make AI work effectively for their needs [8][9]. Many industries still rely on manual or outdated processes, leaving critical workflows undigitized. As TVN Reddy, CEO of Aptean, puts it:
"If key workflows haven’t been digitized, or critical steps aren’t being captured, your AI has nothing to learn from. This creates blind spots in AI predictions." [6]
A real-world example highlights this issue: a North American hospital’s AI initiative failed because the necessary data was scattered across 20 legacy systems, making it nearly impossible to retrieve and analyze [10]. Data silos – where departments keep information in isolated systems – only make things worse, as AI needs access to cross-functional datasets to operate effectively. While 72% of organizations have policies to manage data risks, accessibility remains a bigger challenge [8]. On top of that, poor data quality – think incomplete, outdated, or inconsistent information – leads to skewed results and unreliable insights [6].
Even when data is available, the complexity of custom workflows in these industries poses another major obstacle.
Complex and Custom Workflows
Industries like healthcare, law, and manufacturing rely on highly intricate, customized processes that are difficult to standardize. This creates a tough environment for AI integration. In fact, 53% of companies cite legacy system incompatibility as one of the biggest challenges when scaling AI [11]. These older systems, often built decades ago, were never designed to work with modern AI. As one expert vividly describes:
"Plugging an AI layer into these environments is like installing a jet engine on a bicycle." [12]
To make AI work, organizations often need to redesign entire decision-making processes, which can disrupt operations and face resistance from within [13]. Generic AI models, while impressive on paper, often fall short in specialized tasks like analyzing medical histories or handling legal documentation [1]. Researchers refer to this gap as the "AI chasm" – models perform exceptionally well on standardized tests but fail in real-world, high-stakes scenarios due to their sensitivity to small variations [1][13]. It’s no surprise, then, that up to 85% of AI projects fail to deliver tangible business value, often because of poor planning or integration issues [11].
Even if workflows are streamlined, fragmented data remains a persistent roadblock.
Isolated and Fragmented Data
When datasets are fragmented, AI is forced to make decisions based on incomplete information, which can introduce selection bias. This underrepresentation of certain groups or conditions can lead to inaccurate or unfair outcomes [13][4].
For instance, researchers at the University of Michigan analyzed an Epic Systems AI model designed to detect sepsis. The results were alarming: the model missed 66.6% of actual sepsis cases and produced numerous false alarms, underscoring the gap between controlled lab performance and the complexity of clinical environments [13]. Similarly, when Google deployed a deep learning system for diabetic retinopathy in Thailand clinics in 2020, the model struggled to process real-world images that were of lower quality than its training data. This led to inconsistent results and frustration among medical staff [4].
Bias in Standard AI Models
Standard AI models, often trained on broad datasets, tend to embed biases by relying on superficial correlations. Machine learning algorithms naturally follow what researchers call the "path of least resistance", focusing on the simplest features to differentiate outcomes rather than the most meaningful ones [4].
"AI models typically use only the minimally complicated set of features required to reliably discriminate… taking a ‘path of least resistance’ during its learning." [4]
A 2019 study by Obermeyer et al. revealed severe racial bias in a commercial algorithm used for managing health populations. The algorithm used historical healthcare costs as a proxy for health needs, which led to lower risk scores for Black patients compared to White patients with similar health conditions. This effectively reduced access to care for Black patients [13]. Another challenge is out-of-distribution generalization: when models trained on specific demographics or protocols are applied to different real-world settings, their performance often plummets. For example, general-purpose AI like ChatGPT achieved just 12% accuracy in certain biomedical question-answering tasks, while a specialized adaptation, GeneGPT, reached 83% [14]. These examples highlight how biases in generalized AI models can severely limit their effectiveness in specialized industries.
Make your LLM app a Domain Expert: How to Build an Expert System – Christopher Lovejoy, Anterior
How to Overcome Domain-Specific AI Barriers
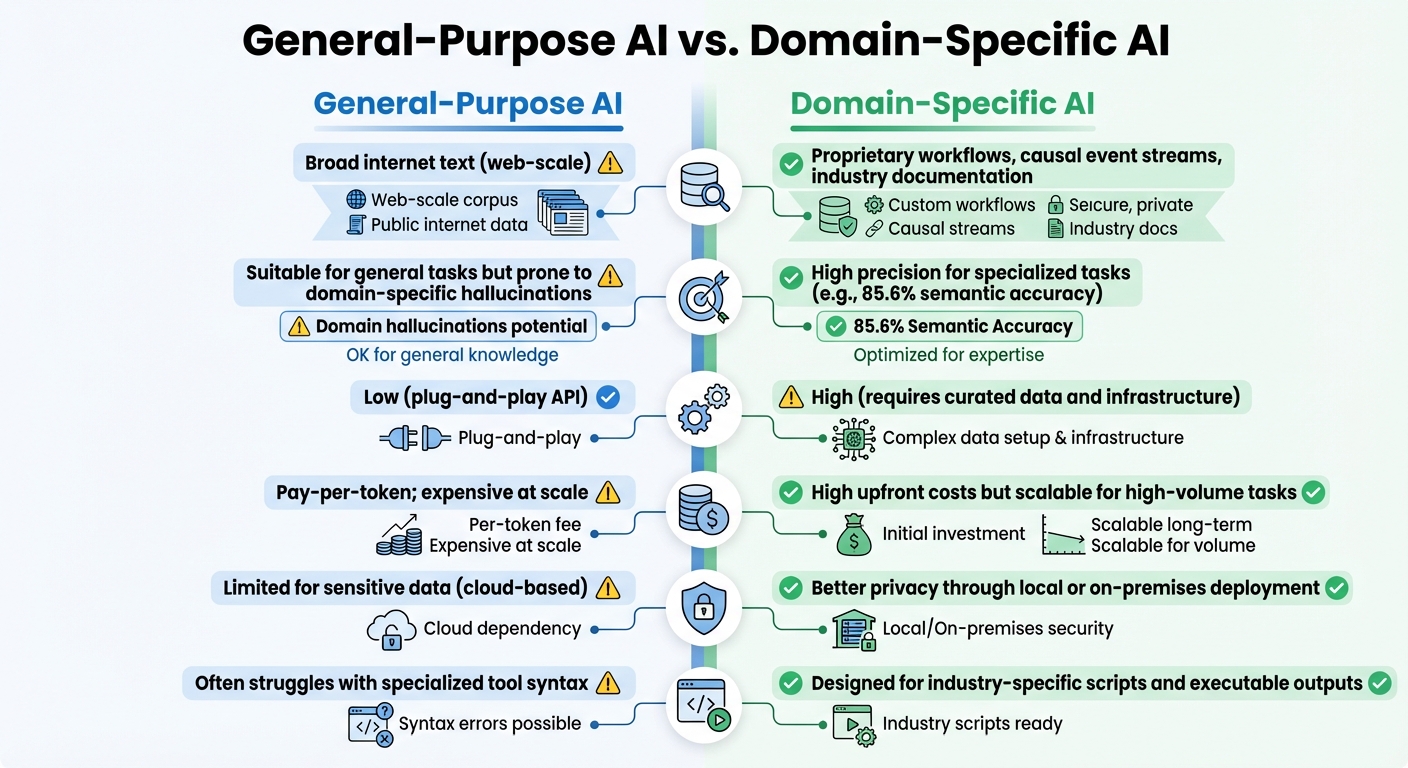
General-Purpose AI vs Domain-Specific AI: Key Differences
Training AI with Your Own Data
One common mistake startups make is feeding raw documents directly into AI models. Simply using unstructured domain text can hinder a model’s ability to respond effectively to prompts [16]. Instead, it’s better to reformat your proprietary data into structured Q&A tasks. This allows the model to practice summarization, reasoning, and answering questions based on your specific content.
For example, in July 2024, Microsoft researchers introduced AdaptLLM, a 7-billion parameter model trained using reading comprehension tasks across fields like biomedicine, finance, and law. By converting raw financial news and legal opinions into structured tasks, AdaptLLM delivered performance comparable to the 50-billion parameter BloombergGPT [16].
If your proprietary data is limited, synthetic data generation can fill the gap. In January 2026, researchers developed TcadGPT for semiconductor Technology Computer-Aided Design by generating 1.5 million synthetic Q&A pairs from expert documentation. This helped the model achieve an 80.0% syntax pass rate on executability tests, surpassing GPT-4o [17]. To get started, conduct an AI readiness audit to identify the minimum amount of data required for effective workflows [18]. Next, let’s explore how real-time retrieval can boost accuracy.
Using Retrieval-Augmented Generation (RAG)
RAG allows AI to retrieve facts in real time from verified sources rather than relying solely on memorized information. This approach is especially useful for domains that require precision, as it grounds responses in specialized datasets, reducing hallucinations and improving accuracy.
Take WikiChat, for instance – a RAG-based system designed to minimize hallucinations. By sequentially querying Wikipedia, filtering facts, and performing self-reflection, it outperformed GPT-4 in factual accuracy by 55% in question-answering tasks [3]. Similarly, TcadGPT used RAG and schema-first alignment to achieve 85.6% semantic accuracy in semiconductor engineering, showing how retrieval enhances both factual reliability and technical precision [17].
RAG not only improves performance but also cuts costs. It can deliver GPT-4-level results at 58% lower costs while significantly reducing hallucinations [15]. Start by experimenting with prompt engineering to see if a generic model can handle your domain tasks. If performance falls short, focus on optimizing chunking algorithms and embeddings. High-quality retrieval depends on these elements. For production environments, consider GPU-accelerated embedding generation to avoid bottlenecks during retrieval [19].
Creating Custom AI Models for Your Industry
While proper data formatting and retrieval systems are essential, custom models tailored to your industry provide the precision needed for specialized tasks. Domain-specific models trained on workflows and causal event data – timelines of actions and outcomes – are far more reliable for high-stakes applications than general-purpose alternatives.
For example, MedPaLM, a version of the 540-billion parameter PaLM model, was adapted for the medical field through instruction tuning. This adjustment enabled it to achieve 67.6% accuracy on US Medical Licensing Exam–style questions, highlighting the value of domain-specific alignment [3]. In industries requiring executable outputs, such as engineering, models should be trained with intermediate representations to ensure code accuracy and proper syntax [17].
Techniques like LoRA and Dynamic Context Tuning make it easier to adapt models with minimal overhead – requiring less than 0.2% of resources. These methods have been shown to improve multi-turn task accuracy by 14% and reduce hallucinations by 37% without the need for full retraining [15]. For sensitive industries like healthcare or legal tech, incorporating human-in-the-loop workflows ensures that AI-generated actions are reviewed and approved before implementation [18].
Comparison: General-Purpose AI vs. Domain-Specific AI
To summarize, here’s a side-by-side look at how general-purpose AI compares with domain-specific AI:
| Factor | General-Purpose AI | Domain-Specific AI |
|---|---|---|
| Training Data | Broad internet text (web-scale) | Proprietary workflows, causal event streams, industry documentation [2] |
| Accuracy | Suitable for general tasks but prone to domain-specific hallucinations [3] | High precision for specialized tasks (e.g., 85.6% semantic accuracy) [17] |
| Integration Effort | Low (plug-and-play API) | High (requires curated data and infrastructure) [3] |
| Cost | Pay-per-token; expensive at scale [3] | High upfront costs but scalable for high-volume tasks [3] |
| Compliance | Limited for sensitive data (cloud-based) | Better privacy through local or on-premises deployment [20] |
| Executability | Often struggles with specialized tool syntax [17] | Designed for industry-specific scripts and executable outputs [17] |
sbb-itb-51b9a02
AlterSquare‘s Step-by-Step Approach to AI-Enabled MVPs
Incorporating AI into software for industries with complex workflows requires a deliberate, structured approach. AlterSquare’s I.D.E.A.L. framework lays out a clear path for startups to integrate AI in a way that aligns with specific industry needs, avoiding generic solutions. This method ensures AI models are tailored to real-world challenges.
Discovery & Strategy
The journey begins with pinpointing the problem and assessing whether AI is the right tool for the job. AlterSquare conducts in-depth research into industry workflows, data requirements, and the roles of key users [22]. This phase involves assembling cross-functional teams – domain experts, data scientists, and project managers – to set clear priorities. For example, in healthcare, this might involve targeting a critical issue like reducing mortality rates [21].
A crucial step here is verifying the availability of real-time data and ensuring that only reliable, actionable data is used [22]. In one case, a six-month due diligence process was undertaken for a sepsis prediction project to confirm the readiness of the data pipeline [22]. This level of preparation minimizes future integration headaches and sets a solid foundation for the project.
Design & Validation
Once a strategy is in place, the focus shifts to designing AI solutions that function as workflow tools rather than simple dashboards. AlterSquare employs a human-in-the-loop process, where experts provide feedback to refine the model’s learning. For instance, in a project predicting traumatic brain injuries, this iterative approach boosted the model’s AUC score from 0.75 to 0.91 [23].
Prototyping with end-users early in the process ensures that the AI solution integrates seamlessly into existing workflows. Additionally, by creating modular outcome definitions – developing models for multiple criteria – the solution remains flexible and can adapt to changing industry standards [22]. This phase lays the groundwork for smooth development and dependable post-launch performance.
Agile Development and Launch Preparation
During development, the focus is on building real-time data pipelines that can pull information from legacy systems, ensuring predictions remain timely and actionable [21]. Before full deployment, "silent trials" are conducted. These trials test the system on live data without disrupting ongoing workflows, ensuring it performs as expected in real-world conditions [22].
AlterSquare also plans for model simplification studies to ensure the AI operates efficiently within the existing infrastructure’s computational limits [22]. Additionally, organizations may need to adjust team roles to align with the AI’s objectives, reducing resistance to adoption [21]. After launch, continuous support ensures the system evolves alongside industry demands.
Post-Launch Support
AI integration is an ongoing process. AlterSquare offers lifecycle management, which includes continuous monitoring, regular data updates, and ensuring compliance with industry regulations [22][24]. This ongoing improvement ensures that the product stays competitive as standards and expectations shift.
This structured approach helps startups avoid common mistakes. For example, 74% of companies implementing AI fail to generate meaningful value from their efforts [7]. By addressing specific challenges at every stage, AlterSquare ensures that AI integration leads to measurable outcomes rather than becoming an expensive misstep.
Real Examples: AI Integration in Domain-Heavy Industries
Healthcare: AI-Powered Diagnostics
From 2021 to 2025, AlterSquare collaborated with the British Columbia Cancer Registry (BCCR) to address a significant challenge: a two-year backlog in coding pathology reports. Human registrars were overwhelmed by the volume of data, making it difficult to keep up. By teaming up with Lovedeep Gondara and Raymond Ng, AlterSquare introduced NLP models to automate the extraction of critical data from these reports.
The results were striking. The false positive rate dropped from 40% to 10%, and the time required to process 1,000 reports plummeted from 1,400 minutes to just 550 minutes [5]. While technical accuracy was important, the dramatic time savings proved to be the game-changer for the BCCR. These advancements in healthcare hint at similar operational efficiencies that other industries could achieve.
Finance: Automating Compliance and Risk Management
After its success in healthcare, AlterSquare turned its attention to the finance sector, where tailored AI solutions delivered equally impactful results. Partnering with a startup, the company developed AI tools designed to automate compliance checks and identify risks in real time. The goal was clear: reduce labor costs while speeding up the deployment of risk mitigation features. To ensure accuracy, the project included a human-in-the-loop system, where experts reviewed complex or uncertain cases flagged by the AI [5].
The benefits were immediate. Processing times were slashed, operational costs dropped, and the startup achieved a solid return on investment. With 81% of organizations now conducting regular risk assessments for AI-related threats, the startup also implemented stringent governance measures to address bias and ensure compliance with regulations [8].
Legal Tech: Improving Document Analysis
In the legal tech industry, AlterSquare applied its expertise to tackle the complexities of document analysis. For a legal tech platform, the team developed an AI solution that streamlined the review of legal documents. Using a hybrid approach, they combined regular expressions for simple, pattern-based tasks with large language models capable of interpreting intricate legal language. This "cascade" method balanced cost and performance by reserving advanced AI for the most challenging cases [5][25].
The system automated tasks like contract review and clause extraction, freeing legal professionals to concentrate on higher-value strategic work. This innovation not only reduced document processing times but also allowed legal teams to operate more efficiently [26].
Conclusion and Key Takeaways
Main Challenges to Address
The road to adopting AI in domain-intensive software isn’t without its hurdles. One major issue is data scarcity, which 42% of industry leaders have identified as a significant obstacle [9]. On top of that, the lack of transparency in decision-making – especially in critical areas like healthcare and finance – raises serious legal and reputational concerns. A single misstep in operations-heavy industries can erode trust, making reliability a non-negotiable requirement. These challenges highlight the need for thoughtful and strategic solutions.
Practical Solutions That Work
To overcome these barriers, the focus must shift toward achieving business outcomes rather than chasing perfect accuracy. As Lovedeep Gondara from the British Columbia Cancer Registry explains:
"The ultimate goal of implementing automated NLP approaches in a healthcare setting is not solely to maximize model accuracy, but to achieve specific business objectives such as improving efficiency" [5].
Startups that thrive in this space often adopt a hybrid approach. For instance, they combine fine-tuned models with Retrieval-Augmented Generation (RAG) to ensure AI outputs are grounded in verified, industry-specific data. Simple techniques like regular expressions are paired with advanced Large Language Models (LLMs), creating a balanced system. Crucially, human oversight plays a central role in high-stakes decisions. AlterSquare’s I.D.E.A.L. framework exemplifies this approach by embedding these principles from the start, ensuring AI solutions align seamlessly with actual business workflows rather than theoretical ideals.
Building Scalable AI Integration
Scaling AI in domain-heavy industries requires a clear strategy. This begins with mapping workflows and collaborating with experts who understand both the technology and the specific domain. The numbers tell a compelling story: while the AI market is expected to reach $1.8 trillion by 2030, growing at an annual rate of 35.9% [29], only 25% of AI initiatives deliver their expected ROI [27]. Moreover, over 80% of enterprise leaders report no measurable impact on EBIT after deploying Generative AI [28].
The key to success? Partnering with those who grasp the nuances of your industry and tailoring AI solutions accordingly. Startups that focus on early wins, establish continuous learning processes, and align AI with domain expertise are the ones that scale effectively. With the right strategy – and experienced partners like AlterSquare – AI integration in complex industries isn’t just feasible; it’s already transforming how businesses operate.
FAQs
Why is it difficult to find enough data for AI in specialized industries?
Data scarcity poses a significant challenge for AI in specialized fields like healthcare, finance, and legal tech. These industries demand high-quality, domain-specific data to train models that can handle their unique complexities. Unlike general-purpose AI, these fields require data that mirrors intricate workflows and industry-specific details. However, accessing such data is often difficult due to strict privacy laws, proprietary limitations, or the rarity of certain scenarios.
On top of that, specialized data usually needs expert annotation – a process that’s both time-intensive and costly. This further restricts its availability, making it harder for AI systems to achieve reliable performance. As a result, adoption in these industries often slows, and the potential impact of AI is diminished. To tackle these issues, many organizations are now prioritizing the development of strong data ecosystems, reusable datasets, and effective data governance practices to bridge the gap.
How does Retrieval-Augmented Generation (RAG) make AI more accurate?
Retrieval-Augmented Generation (RAG) takes AI accuracy to the next level by combining the power of large language models (LLMs) with external, reliable knowledge sources. Rather than relying solely on pre-existing training data, RAG actively pulls in relevant, up-to-date information from external databases or documents. The result? More precise and factually accurate responses.
This method shines in industries like healthcare, legal tech, and finance – fields where detailed, domain-specific knowledge and accuracy are non-negotiable. By connecting general AI capabilities with specialized information, RAG minimizes issues like outdated data or hallucinations, making AI-generated outputs more reliable and practical for real-world applications.
Why is human oversight essential when using AI in specialized industries?
Human involvement is essential when integrating AI into specialized fields like healthcare, legal tech, or finance. These industries rely heavily on expert judgment and a deep understanding of context to navigate complex workflows and interpret nuanced data – areas where AI models may fall short.
While AI systems can offer helpful insights, their accuracy depends on the quality of the data they’re trained on. Human experts are indispensable for validating AI-generated outputs, spotting potential mistakes, and ensuring decisions meet the unique standards of their industry. Take radiology, for instance: when AI tools work alongside radiologists, diagnostic accuracy improves by blending the computational abilities of AI with the professional expertise of doctors.
This kind of collaborative approach, where AI complements rather than replaces human decision-making, is the key to successfully scaling AI in specialized domains. It strikes a balance that not only improves results but also addresses the distinct challenges these industries face.







Leave a Reply